
[Kafka] 1. kafka란 무엇인가?

Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
이번에 학부연구생을 시작하면서 Kafka를 사용하게 되었다. 정말 처음 들어보는 것이라서 약간 걱정은 되지만, 포기할거였으면 시작을 하지 않는 나이기에 잘 할 수 있을 것이라고 믿는다!
1. Kafka란 무엇인가?

공식 설명에 의하면 Kafka는 distributed event streaming flatform이다. 내가 이해한 바를 이용해 간략하게 정의하면 Kafka는 System간 data를 공유할 때 유용하게 사용할 수 있는 플랫폼이다. Kafka는 1초당 수백만개의 데이터 포인트를 처리할 수 있어 빅데이터 분야에서 좋은 역할을 하고 있다. IoT나 소셜미디어와 같은 여러 데이터를 처리해야하는 사례의 경우 데이터가 기하급수적으로 늘어나고 있기 때문에 앞으로 점점 확장성이 중요해질 것이다. 이때 확장성을 지원해줄 수있는 것이 Kafka이다.
2. Kafka의 기본 구조
Kafka는 기본적으로 Kafka cluster, Producer, Consumer, Zookeeper로 구성되어 있다.

1) Kafka cluster
Kafka cluster가 기본적으로 데이터를 저장하는 저장소와 같은 역할을 한다. publish, subscribe 과정에서의 메시지 관리를 담당하며, topic으로 구성되어 있다.
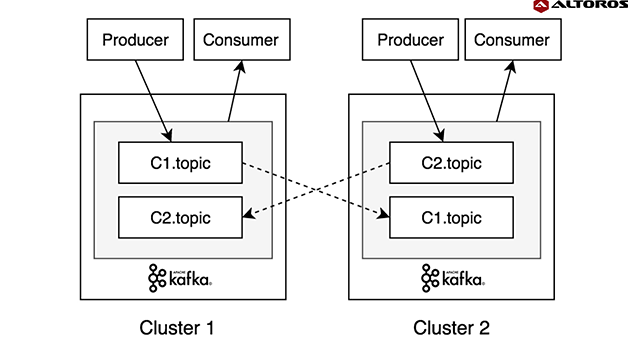
topic은 message를 저장하는 단위이며 broker가 topic릉 저장하고 처리한다. 1개의 topic은 1개 이상의 파티션으로 나누어져 있다. 파티션은 append-only 파일이며 message queue 형식으로 처리되어진다. 파티션으로 분리하면 데이터의 처리량을 높일 수 있다. kafka의 특징 중 하나인 '분산'이 잘 들어나는 부분 중 하나로 하나의 topic에 publish 되는 데이터가 분산되어지고 파티션 각각도 분산되어 저장된다.

위의 내용을 종합해보면 정리해보자면 Kafka cluster에는 broker에 topic 단위로 메시지가 저장된다. 이때, message는 여러개의 파티션으로 이루어져 있고 이는 message queue 형식을 따른다.
2) Producer
message를 생산, 발송하는 역할을 한다. 원하는 message를 브로커에 전송할 수 있도록 변환시키고 필요한 값을 지정해주는 과정을 수행한다.
직렬화 ( Serializer )
파티셔닝 ( Partitioner )
메시지 배치 (Record Accumulator )
압축 ( Compression )
전달 ( Sender )
프로듀서는 가장 먼저 전달받은 메시지를 직렬화한다. 이때 메시지의 키와 값은 바이트로 변환된다. 직렬된 메시지는 topic의 어떤 partition에 저장될지 결정된다. 이 과정을 파티셔닝이라고 하며, 별도의 설정이 없다면 round robin 형태로 파티셔닝을 한다. ( 특정 파티션에 저장되라는 설정이 있는 경우 그냥 그 곳에 저장 된다 )
이후, 필요에 따라 메시지를 압축시키고 브로커에게 전달한다. 프로듀서는 TCP 프로토콜을 통해 브로커 reader partition으로 이동한다. 이때, 매번 네트워크를 통해 전송하는 것이 아닌 지정된 만큼 저장했다가 한 번에 브로커로 전송이 된다. 이 과정은 RA가 진행하는데 RA는 Batch Queue를 구성해 메시지를 저장한다. 저장된 메시지는 sender의 도움을 받아 전송이 된다. sender thread는 피기백 방식으로 브로커로 전송한다.
+) round robin이란?
스케쥴링의 한 방법으로 다중 처리에서 태스크의 실행 순서를 사이클릭으로 실행하는 방법 등에 사용된다.

간단하게 생각하면 순서대로 처리하니까 모든 task를 공평하게 진행할 수 있게 도움을 준다.
+) 배치란?
일괄적으로 작업을 처리한다는 의미로 토픽의 처리를 할 때마다 작업을 하는 것이 아닌 백그라운드로 이동시켜 일괄적 처리를 한다는 것이다.
+) piggyback이란?
piggyback은 등에 업는 것을 의미한다. 수신측에서 수신된 데이터에 대해 확인 응답을 즉시 보내거나 제어 프레임을 사용하지 않은 채 전송할 데이터가 있는 경우에만 사용되는 오류제어 방식이다. 데이터 프레임 안에 확인 필드를 덧붙인다는 의미로 piggyback이라는 용어가 사용되었다.
3) Consumer
topic을 가져와서 소비하는 역할을 한다. 간단히 말하자면 메시지를 가져와서 소비하는 애플리케이션, 서버 등을 지칭한다고 생각하면 된다. consumer의 주요 기능은 특정 파티션을 관리하고 있는 파티션 리더에게 메시지를 가져오라고 요청하는 것 이다. 이때, offset을 명시해 위치를 표현한다.
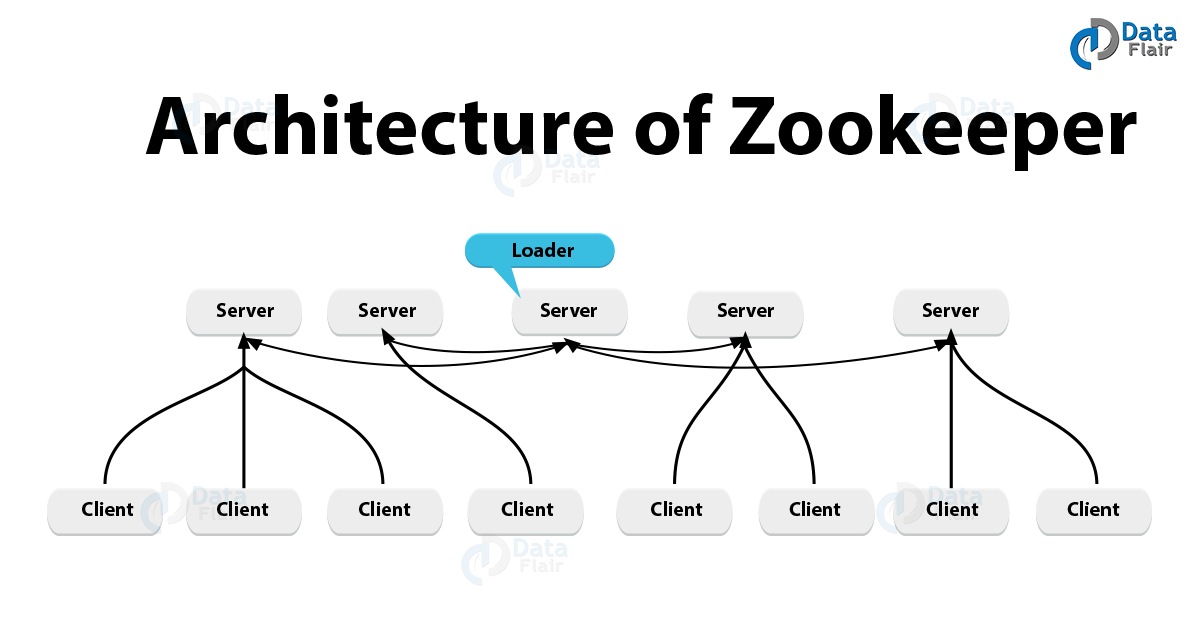
4) Zookeeper
kafka의 상태관리 등의 목적으로 이용되는 것으로 분산 애플리케이션을 위한 코디네이션 시스템이다. 각 정보를 중앙에 집중시키고, 구성, 네이밍, 동기화 등의 서비스를 제공한다.
3. Kafka의 장점
kafka는 묶어서 받고 보내는 것이 가능하기 때문에 전체적인 처리량이 높아진다. 그리고 장비가 한계일 때 브로커와 파티션을 추가하는 방법으로 컨슈머가 느리다면 파티션을 늘리거나 컨슈머를 추가하는 방식으로 해결할 수 있다.
'Develop > Kafka' 카테고리의 다른 글
| [Kafka] 2. kafka-python 으로 kafka producer, consumer 만들기 (0) | 2023.01.12 |
|---|





