
[AI] 시계열 데이터와 순환신경망 (RNN, LSTM)
시계열 데이터
시계열 데이터란?
시간 축을 따라 신호가 변하는 동적 데이터
심전도, 주식, 음성인식 등이 있다.
시계열 데이터 특성
- 요소의 순서가 중요하다. (time dependency)
- 샘플의 길이가 다르다.
- 문맥 의존성 (context dependency) 를 가진다.
- 계절성(seasonality)을 가지는 데이터가 있다.
시계열 데이터 표현
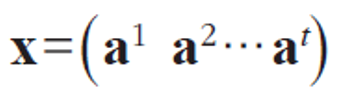
(가변길이, 벡터의 벡터로 구성)
시계열 데이터 구조
- 윈도우 크기 (w) : 문제의 이전 요소를 얼마나 볼 것인가?
- 수평선 계수 (h) : 얼마나 먼 미래를 예측 할 것인가?
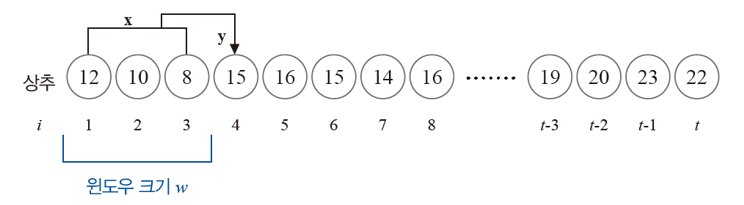
데이터가 다중 품목을 표현하고 있을 수도 있다.
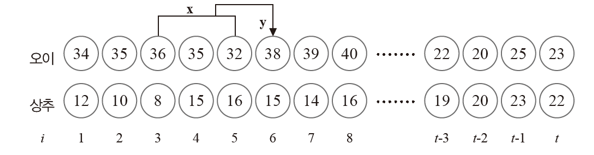
다중 채널의 데이터는 벡터의 벡터 구조로 표현하면 된다.
X1 = ((34,12), (35,10), (36,8))
Y1 = (35, 15)
# 시계열 데이터를 window 단위로 잘라 가공하는 함수
def seq2dataset(seq, window, horizon):
X = []; Y = []
for i in range(len(seq) - (window + horizon) + 1 ):
x = seq[i:i+window]
y = seq[i+(window+horizon)-1]
X.append(x); Y.append(y)
return np.array(X), np.array(Y)
순환신경망(RNN)
순환신경망 (Recurrent neural network)는 인공신경망의 한 종류로 유닛간의 연결이 순환적 구조를 갖는 특징을 가지고 있다.
기본 형태
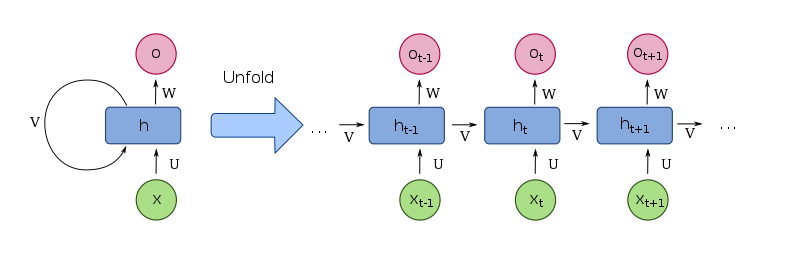
은닉층 노드 사이에 순환 edge가 있어 순간마다 서로 다른 가중치를 가지는 것이 아닌 가중치를 공유하는 특성이 있다.
수식적 표현 및 동작
순환신경망은 최적의 {U, V, W} 를 찾는 것이 목적이다.
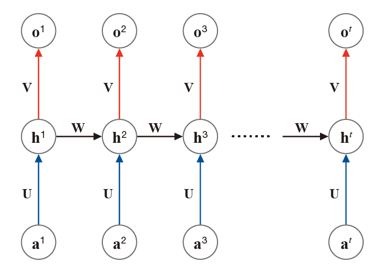
- a: input
- h : hidden variable
- o : output
(ai는 i 순간에 입력되는 input, oi는 i 순간에 출력되는 output을 의미함)
은닉층에서 일어나는 계산
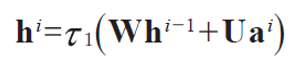
출력층에서 일어나는 계산
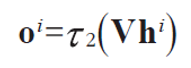
은닉층의 Whi-1 항을 제외하면 다층 퍼셉트론과 동일한 형태를 가지고 있다.
순환 신경망 사용 예제
- 미래 예측 ( 주가, 날씨, 기계고장, 비트코인 등)
- 언어 번역
- 음성 인식
- 생성 모델
순환 신경망의 한계
- 은닉층 상태를 다음 순간으로 넘기는 기능을 통해 과거를 기억하지만, 장기 문맥 의존성이 낮다. ( 멀리 떨어진 요소가 밀접한 상호작용을 하는 상태)
- 계속 들어오는 입력의 영향으로 기억력이 감퇴된다.
LSTM
LSTM ( Long Short-Term Memory) 은 순환신경망에 선별 기억을 확보하여 장기 문맥 의존성을 높인 모델이다.
원리
게이트라는 개념으로 선별 기억을 확보하였다.
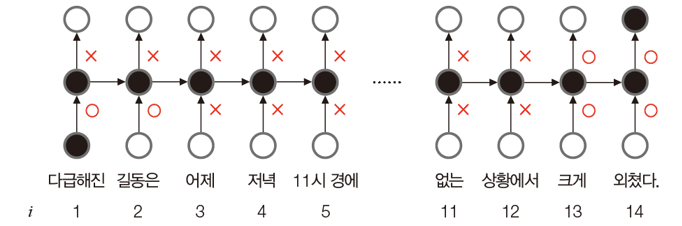
gate는 0~1 사이의 실수 값으로 열린 정도를 조절하며, 위 그림에서는 O가 열린 상태이고, X는 닫힌 상태이다.
가중치
순환신경망 : {U, V, W}
LSTM : {U, Ui, Uo, W, Wi, Wo, V} ( i는 입력 게이트, o는 출력 게이트 )
LSTM 의 다양한 구조
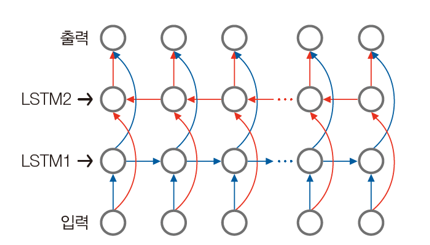
양방항으로 문맥을 살필 필요가 있으면 양방향 LSTM을 사용한다.
- 적층 LSTM ( stacked LSTM )
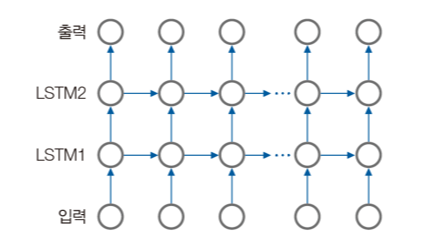
- 양방향 LSTM ( bidirectional LSTM )
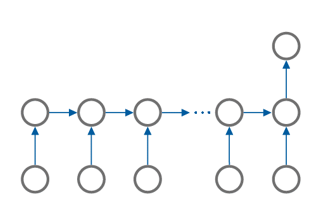
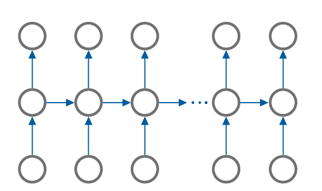
응용 문제에 따라서도 다양한 구조를 만들 수 있다.
- 분류, 예측 문제 (many to one)
- 비디오 프레임 분류 (many to many)
- 언어 번역 (many to many)

순환신경망, LSTM의 활용
편곡하는 인공지능
LSTM을 활용해 앞 소절을 보고 다음 음표를 예측 하는 방식의 단순한 편곡이 가능하다. 하지만, 높은 수준의 편곡은 생성모델(generative model)을 이용해야한다.
자연어 처리
자연어 처리 (NLP) : 인간이 구사하는 언어를 자동으로 처리하는 인공지능 분야로 언어 번역이나 chatbot 등에 사용된다.
텍스트 데이터의 특성
- 시계열 데이터이며 샘플마다 길이가 다르다
- 잡음이 심하다
- 형태소 분석이 필요하다
- 구문론과 의미론
- 다양한 언어 특성
- 신경망에 입력하려면 기호를 수치로 변환해야한다.
텍스트 데이터의 표현
1. 윈핫 코드 표현
단어들을 수집하고 빈도수로 정렬을 한 다음 숫자 부여 -> 텍스트를 숫자 코드로 변환


그리고 이 숫자를 원핫 코드로 변형 시킨다.

하지만, 원핫코드는 사전 크기가 클 수록 너무 길어지며, 단어 상이의 연관 관계를 반영하지 못한다.
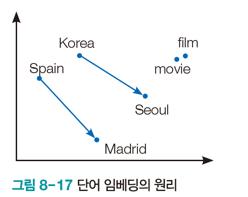
2. 단어 임베딩
단어를 저차원 공간의 벡터로 표현하는 기법으로 보통 수백 차원을 이용한다. ( 수백차원이지만 원핫코드 방식보다 차원이 낮다. )

단어 임베딩을 사용하면 단어 간의 관계성도 알아낼 수 있다.
'Computer Science > AI' 카테고리의 다른 글
| [MIT 6.S191] Recurrent Neural Networks, Transformers, and Attention (0) | 2023.09.27 |
|---|---|
| [MIT 6.S191] Introduction to Deep Learning (0) | 2023.09.13 |
| [AI] DCNN Architecture (AlexNet, VGGNet, GoogLeNet, ResNet) (0) | 2023.06.11 |
| [AI] 생성 모델 ( 오토인코더, GAN, PixelCNN, PixelRNN ) (0) | 2023.06.11 |
| [AI] 강화 학습과 게임 지능 ( 강화학습, Salsa, Q 러닝, DQN ) (0) | 2023.06.11 |








