
[AI] DCNN Architecture (AlexNet, VGGNet, GoogLeNet, ResNet)
다양한 DCNN 구조에 대해 간단하게 살펴보겠다. 아래에서 살펴볼 4개의 모델들은 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)라는 대회에서 만들어진 모델이다. 2010년부터 2017년까지 진행되었으며 이 대회는 DCNN에 큰 혁신을 일으켰다.

AlexNet (2012)
최초로 DCNN 구조를 사용한 방식이다. 이 방식이 기존의 ML 방식을 크게 뛰어넘게 되고, 이후의 방법에도 큰 영향을 주었다.

구조
5개의 convolution 층과 3개의 FC 층이 있다. 커널을 11*11,5*5,3*3 형태를 사용하였다.


특징
- 활성화 함수롤 ReLU 처음 사용
- FC layer 사이에 dropout 사용
- 데이터 증강 기법 사용
- Batch size 는 128
VGGNet (2014)
2014년의 ImageNet Challenge에서 GoogLeNet과 함께 가장 좋은 성능을 보여준 모델이다. (물론 googLeNet에 밀려 2등을 하긴 했다)

구조
- layer 수 : 16 ~ 19
- Filter 크기 : 3 * 3 단일 크기이다.
- 모든 convolution layer는 same padding을 적용했다.

작은 filter가 가지는 의미
VGGNet은 큰 필터 대신 작은 필터를 여러번 사용하였다. 실제로 3*3 conv layer 3개와 7*7 conv layer 한 개의 receptive field가 동일하다.
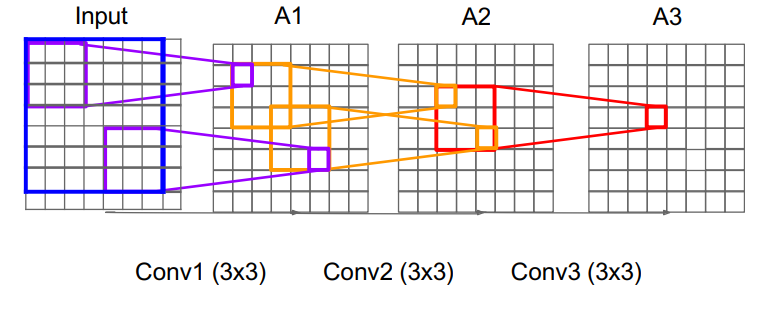
작은 필터는 2가지 장점이 있다.
- filter가 작아서 필요한 패러미터의 수가 줄어든다.
- 더 깊게 쌓을 수 있다. -> 비선형성이 많아진다.

GoogLeNet (2014)
VGGNet과 같이 더 깊은 network 구조로 높은 성능을 낸 구조이다. VGGNet보다 더 좋은 성능으로 1위를 차지하였다.
구조
- layer : 22
- Filter 크기 : 1*1, 3*3, 5*5
- parameter 수 : 5M (VGG의 1/ 27배)

Inception 모듈
GoogLeNet은 Inception 모듈을 가지고 있다. 네트워크 안에 네트워크(NiN)를 가지는 구조로 복잡한 네트워크를 더 간단하게 만들 수 있다.

처음 Inception 모듈은 다양한 convolution filter를 사용하여 다양한 수용 영역 크기를 병합하는 형태로 만들어졌다.

하지만 위의 구조로 계속 층을 쌓다보니 계산량과 필요 메모리가 너무 많아지는 문제점이 발생했다.
- 계산량
[1*1 conv, 128] : 28 * 28 * 128 * 1 * 1 * 256
[3*3 conv, 192] : 28 * 28* 192 * 3 * 3 * 256
[5*5 conv, 96] : 28* 28 * 96 * 5 * 5 * 256
=> 전체 854M - 메모리
28 * 28 * (128 + 192 + 96 + 256 ) = 529K

그래서 convolution layer에 들어오는 모듈 입력의 채널 수를 줄이기 위해 각각의 convolution layer 전에 1*1 convolution을 적용하였다. 그리고 반대로 max pooling 에서는 나가는 모듈 출력의 채널 수를 줄이기 위해 풀링 이후 1*1 convolution 층을 추가하였다.

이렇게 하니 전체 계산량이 854M에서 358M으로 줄어들게 되었고 필요 메모리도 약 200K 정도 줄어들게 되었다.
Loss의 발생
googLeNet의 구조를 보다보면 softmax (loss function) 이 3번 발생하는 것을 확인할 수 있다. 마지막 softmax는 출력층이라고 해도 중간에 있는 것은 굉장히 독특한 모습이다.

이 당시에는 deep CNN이 발전되지 않아 신경망 층을 깊게 쌓으면 역전파 알고리즘이 잘 작동하지 않는 문제가 있었다. 그래서 중간에 loss를 구해 업데이트를 해주는 방식으로 역전파 알고리즘이 잘 작동하도록 해준 것 같다. 논문에서는 auxiliary classifiers 라고 소개되었다.
ResNet (2015)
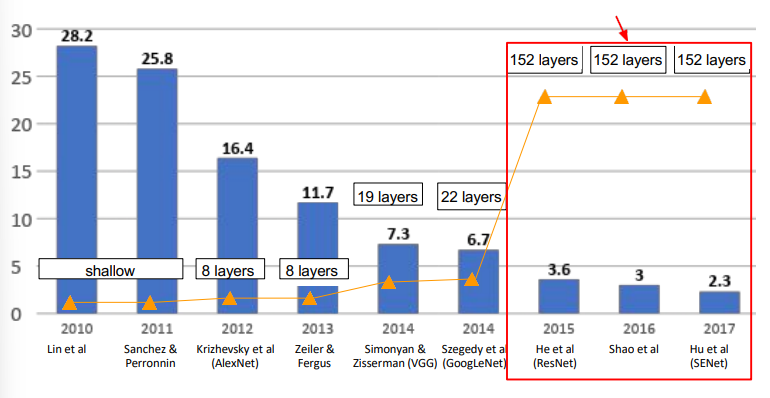
ResNet 아이디어
ResNet 전의 모델들을 살펴보면 신경망 층을 깊게 쌓을 수록 성능 향상이 이루어지는 모습이 보였다. (2010 ~ 2014) 그래서 층을 늘려 쌓은 결과를 살펴보았다.

층을 56개로 늘려본 결과 학습 자체가 되지 않는다는 것을 알게되었다. 깊은 모델일수록 표현력은 높아지나, 학습이 어려워진다는 것이다.
그래서 '이미 학습된 얕은 모델들을 가져와 연결' 하는 방식을 고안해 냈고 이것이 ResNet의 핵심 아이디어이다.
Residual Block
H(x) = F(x) + x
weight layer를 통과한 F(x)와 x를 합을 구한다. (Residual Mapping)
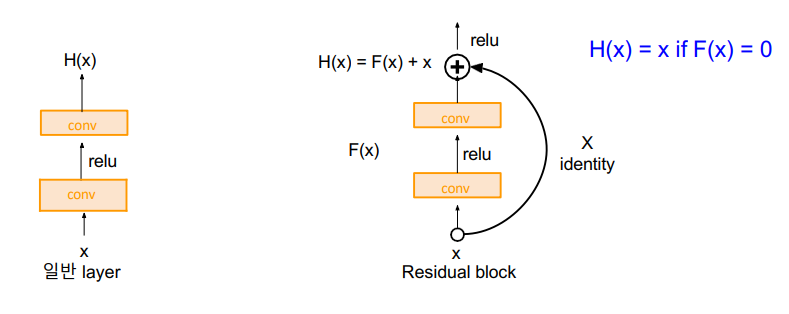
위 식을 정리하면, F(x) = H(x) - x이다. 이 형태가 컨볼루션을 거친 후의 결과과 입력값의 차이이기 때문에 잔차라고 한다.
구조

ResNet은 classification, detection, localization, segmentation task 모든 분야에서 1위를 거뒀다. 또한, top-5 error가 3.6%로 사람(5%) 보다 더 좋은 성능을 보였다.

'Computer Science > AI' 카테고리의 다른 글
| [MIT 6.S191] Recurrent Neural Networks, Transformers, and Attention (0) | 2023.09.27 |
|---|---|
| [MIT 6.S191] Introduction to Deep Learning (0) | 2023.09.13 |
| [AI] 생성 모델 ( 오토인코더, GAN, PixelCNN, PixelRNN ) (0) | 2023.06.11 |
| [AI] 강화 학습과 게임 지능 ( 강화학습, Salsa, Q 러닝, DQN ) (0) | 2023.06.11 |
| [AI] 시계열 데이터와 순환신경망 (RNN, LSTM) (0) | 2023.06.11 |








