
[AI] Ensemble Learning - Voting, Bagging, Boosting, Random Forests
Ensemble
하나의 모델이 아닌, 여러 모델을 함께 사용하여 모델의 성능을 향상 시키는 방법이다. 앙상블을 이용하면 가장 좋은 individual predictor로 도출된 결과보다 더 좋은 결과를 얻을 때가 있다. 여러 predictor를 사용하기 때문에 '집단지성'과 유사하다.
앙상블 기법은 대표적으로 Voting, Bagging, Boosting이 있다. 이에 대해 자세히 알아보자
Voting
다양한 classifier를 이용한 결과를 앙상블하는 기법이다. classifier를 만드는 방법은 다른 classifier를 사용하는 방법도 있고, 하나의 classifier에 random한 subset을 주고 학습하는 법도 있다.
voting을 이용하면 각각은 weak learner 였더라도 서로 결합하여 strong learner의 역할을 할 수 있다.
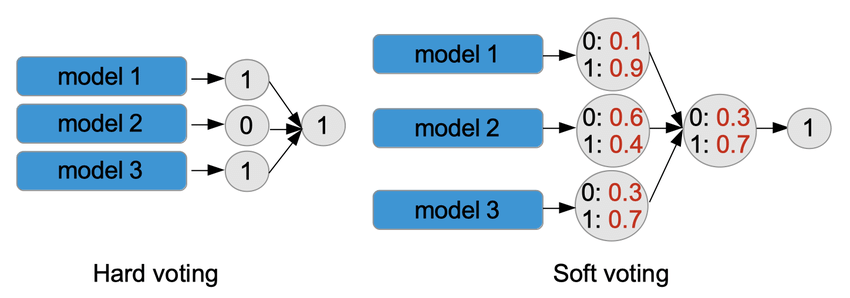
Hard Voting
여러개의 classifier의 결과를 비교해 가장 많이 나온 답을 취한다.

Soft Voting
hard voting은 단순히 결과 값이 다수로 나온 것을 취했는데, soft voting은 각 결과의 확률을 본다. 확률값의 평균을 취해 가장 높은 답을 결과로 사용한다.
Voting의 성능을 끌어올리기 위해서는 최대한 predictor를 독립적이게 선택해야한다. 예를 들어 Decision Tree와 Ramdom Forest를 선택하면 그 둘은 비슷한 성질을 가지고 있기 때문에 다른 predictor를 섞는다 하더라도 결과가 치우칠 수 있다. 최대한 겹치지 않게 다양한 ML을 선택하여 학습하자.
Bagging
모델의 일반화 성능을 낮추는 원인은 크게 3가지가 있다.
- Bias : 데이터 자체를 잘못 가정한 경우 ( quadratic 분포의 데이터셋을 linear라고 생각해 linear model로 예측하면 절대 좋은 결과를 얻을 수 없다. == underfitting )
- Variance : train data의 작은 변화에도 너무 민감하게 결과가 반응하는 경우 ( DT가 대표적인 예시이다. )
- Irreducible error : 데이터가 그 자체로 noise가 있어서 모델로 구분할 수 없는 경우 이럴 때에는 train 데이터를 삭제하는 방법 밖에 없다.
이러한 문제들을 해결하기 위해 training set을 random 한 subset을 뽑아 학습을 시켜보는 방식이 Bagging이다.
Bagging ( Bootstarp Aggregating )
Bagging은 전체 데이터셋에 대해 복원 추출을 통해 모델을 학습시킨다. 학습 데이터가 적더라도 높은 효율을 보인다는 것이 장점이다. Bagging은 말그대로 랜덤하게 복원 추출을 진행하기 때문에 모든 데이터셋에 대해 학습하는 것은 아니다. ( 선택되지 않은 데이터셋이 존재할 수 있다. )
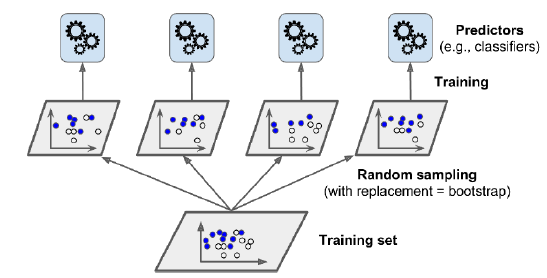
Bootstrapping을 사용하면 subset의 다양성이 높아진다. 즉, 일반화 성능이 높아질 수 있다.

위 DT를 bagging을 사용한 것과 하지 않은 것을 비교한 부분이다. bagging을 이용하니 train set 자체의 예측 성능은 떨어졌다. 하지만, 그만큼 일반화 성능이 높아진 모습을 확인할 수 있다.
Pasting
bagging과 다르게 복원추출이 아닌 한번 데이터셋을 선택하면 선택하지 않는 방법이다.
Random Forests
랜덤 포리스트는 Decision Tree 기법에 bagging을 적용한 방법이다. 여러개의 feature의 random subset 중에서 가장 좋은 성능을 보인 feature을 찾는 것으로 tree의 다양성은 높혀 일반화 성능을 끌어올렸다.
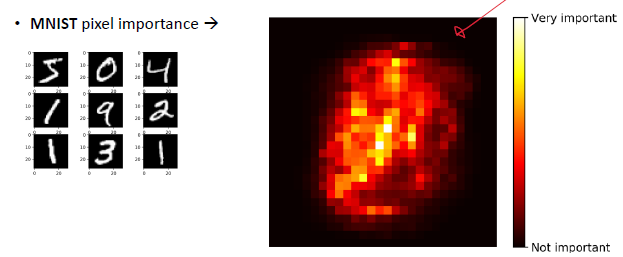
RF는 각 특징의 상대적인 중요성을 측정하기 쉽다.
Boosting
위 두 방식 (voting, bagging)은 predictor 자체의 성능을 끌어올리지는 않았다. Boosting 방식은 이와 다르게 predictor를 순차적으로 학습시켜 더 좋은 성능을 이끈다. 가장 유명한 방식으로는 AdaBoost와 Gradient Boosting이 있다.
AdaBoost (Adaptive Boosting)
앞의 모델이 맞추지 못한 training instance(모델이 예측하기 어려운 케이스)에 초점을 맞춰 보는 것이다.

이전 모델이 맞추지 못한 데이터셋을 뽑아 내야하기 때문에 순차적으로 학습이 진행된다.
Gradient Boosting
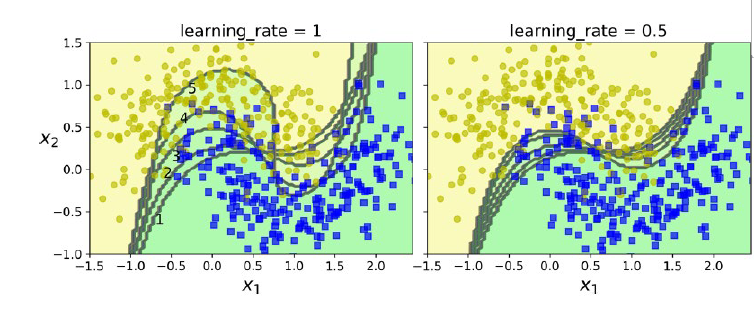
AdaBoost처럼 이전 상황에서 맞추지 못한 상황을 해결하기 위해 순차적으로 진행한다. 다른 점은 residual error(전체 - 맞은 것)를 학습시킨다는 것이다.


위 사진의 붉은 선 부분을 보자. 위쪽이 y를 보고 h1(x)를 학습한 모습을 보여준다. 붉은 선쪽을 보면 초록선(h1(x)) 보다 위쪽에 있는 데이터셋은 아래 그래프에서 0보다 위쪽에 있는 것을 볼 수 있다. 이렇게 차이점을 데이터셋으로 넣어 다시 한번 더 train하면 오차 부분을 보고 정확도를 높일 수 있다.

코드로 보면 이런 식이다. 위 사진을 잘 따라 가면서 살펴보면 충분히 의미를 파악할 수 있을 것이다.
Stacking
지금까지 여러 앙상블 기법들을 살펴보았다. 여기서 한 가지 더 상황이 남아 있다. voting을 진행할 때 모든 모델의 성능이 유사한 수준이라면 투표를 동일한 영향력으로 본다. 하지만, 어떤 모델은 너무 약하고 반면 다른 모델은 강한 상태라서 이에 대한 비율을 조정해야하는 상황이 올 수 있다. 이럴 때는 voting model을 train해야한다.
즉, model을 위해 적용한 voting model을 학습시켜야한다. 이 것이 마치 층을 쌓는 것처럼 보이기에 stacking이라고 한다.
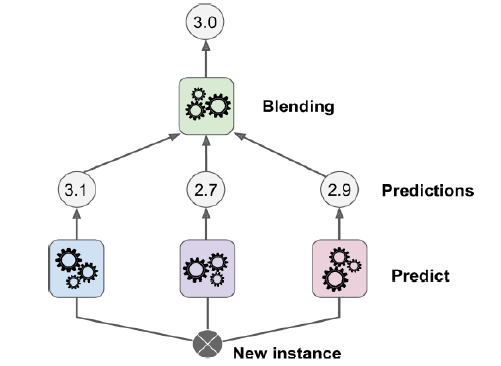
aggregating prediction은 blending predictor를 사용한다.

multiple layer로 쌓을 수도 있다.
요약
- Voting
: Hard Voting, Soft Voting - Bagging / Pasting
: Random Forest - Boosting
: AdaBoost, Gradient Boosting - Stacking
'Computer Science > AI' 카테고리의 다른 글
| [AI] 컴퓨터비전 - 기초 영상 처리 기법 (1) | 2024.04.20 |
|---|---|
| [MIT 6.S191] Convolutional Neural Networks (1) | 2024.02.08 |
| [MIT 6.S191] Recurrent Neural Networks, Transformers, and Attention (0) | 2023.09.27 |
| [MIT 6.S191] Introduction to Deep Learning (0) | 2023.09.13 |
| [AI] DCNN Architecture (AlexNet, VGGNet, GoogLeNet, ResNet) (0) | 2023.06.11 |








