
[MIT 6.S191] Convolutional Neural Networks
All materials are copyrighted and licensed under MIT license.
© Alexander Amini and Ava Amini
MIT Introduction to Deep Learning
IntroToDeepLearning.com
MIT Deep Learning 6.S191
MIT's introductory course on deep learning methods and applications.
introtodeeplearning.com
이 강의 자료에 대한 모든 저작권은 MIT 에 있으며, 관련 자료가 필요하신 분은 위 사이트로 들어가면 누구나 자료를 다운받을 수 있으니 참고하길 바란다.
https://www.youtube.com/watch?v=NmLK_WQBxB4
Contents
- Introduction
- Amazing applications of vision
- What computers "see"
- Learning visual features
- Features extraction and convolution
- The convolution neural networks
- End-to-end code example
- Applications
- Object detection
- End-to-end self driving cars
- Summary
Introduction
CNN에 본격적으로 들어가기 전에 한 가지를 생각해보자.
우리는 세상에 무엇이 있는지, 어디에 그 것들이 존재하는지, 그 것들이 어떻게 움직일건지 어떻게 예측할까?
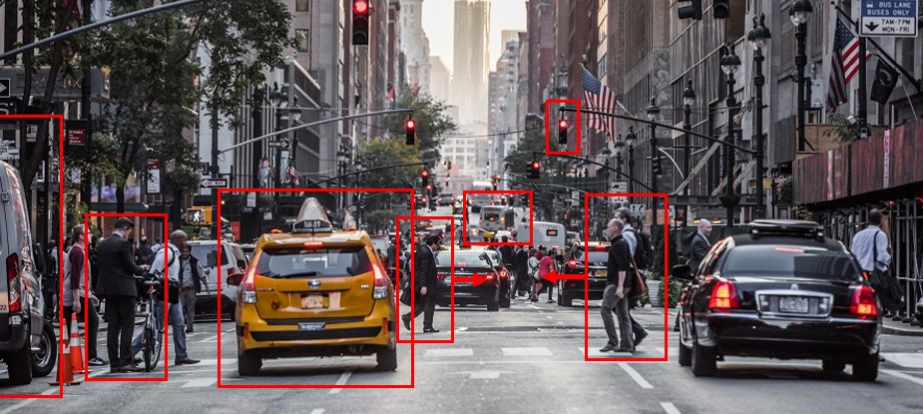
위 그림에서 보면 수 많은 자동차, 신호등, 사람이 있다. 횡단보도에 있는 사람을 보자. 우리는 자연스레 위 이미지를 통해 횡단보도에 있는 사람이 앞으로 이동중이라는 것을 알 수 있다.
computer vision은 컴퓨터에게 이런 task를 가능하게 해줄 수 있다.
Amazing appliciations of vision
computer vision 분야가 향상되면서 다양한 분야에서 발전이 이루어졌다.
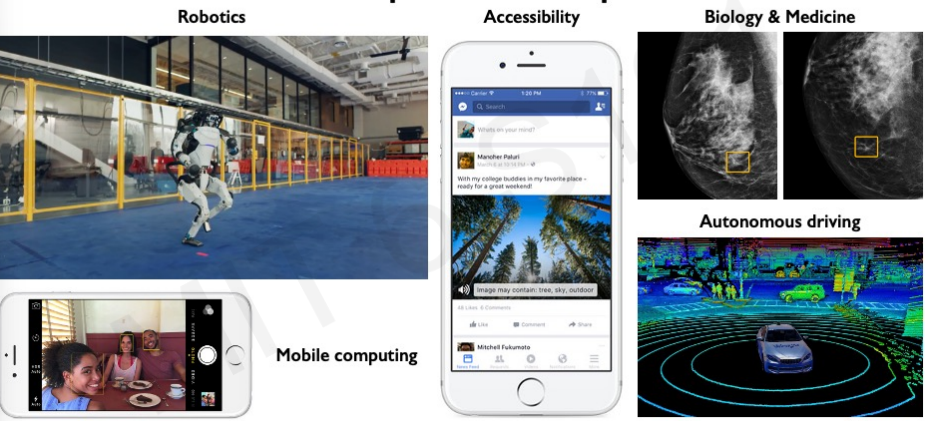
우리 눈으로 할 수 있는 많은 분야들이 AI가 처리할 수 있는 세계가 다가오고 있다.
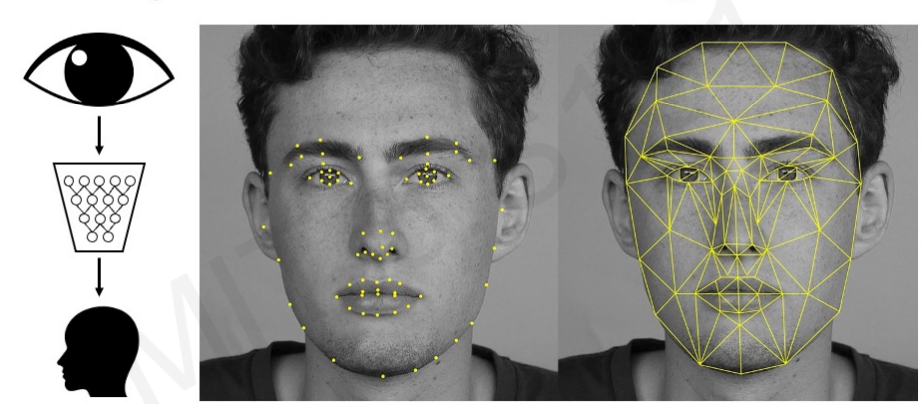
1. Facial Detection & Recognition
2. Self-Driving Cars

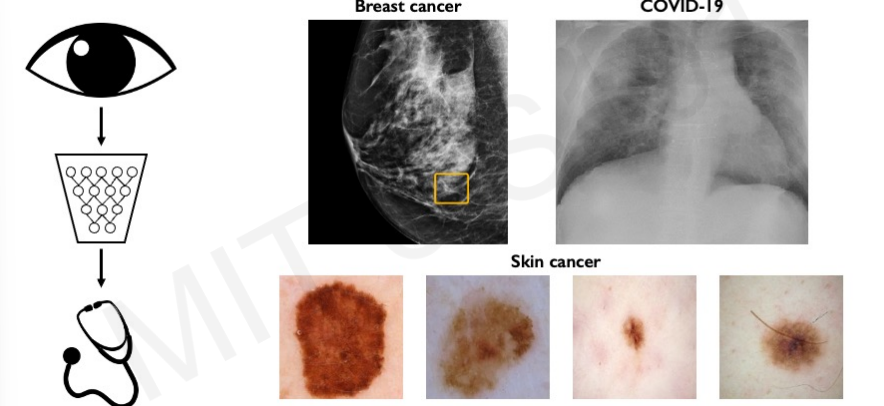
3. Medicine, Biology, Heathcare
4. Accessibility

What Computers "see"
컴퓨터는 이미지를 어떻게 보고 있을까? 이미지는 결국 숫자로 이루어져있다.

흑백 사진의 경우 0~255 사이의 숫자를 진하기에 따라 다르게 부여하여 숫자로 나타낼 수 있다. 만약 color가 포함된다면 각 컬러에 따른 RGB 값을 추가하여 표현할 수 있다.
우리는 이미지를 이미지로 보지만, 컴퓨터는 이미지를 픽셀단위로 표현하여 분석하고, 그 이미지가 무엇인지 파악한다. 아래 사진이 컴퓨터가 이미지를 분류하는 과정이다.
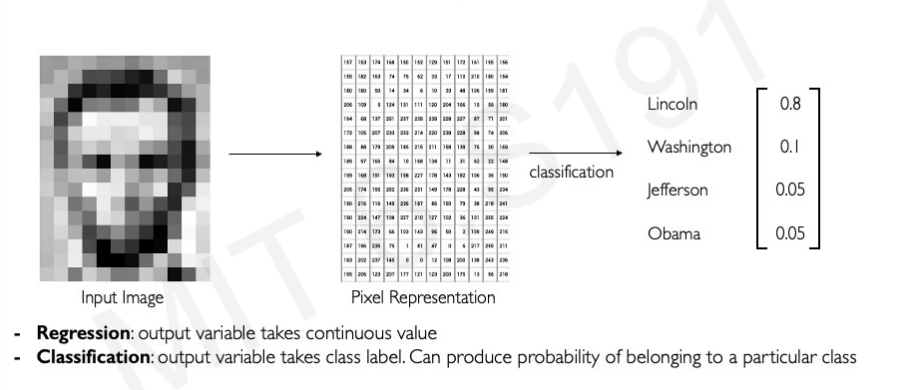
단순히 어떤 사람인지 분류하는 것이 아니라 각각의 이미지 카테고리가 어떤 key feature를 가지고 있는지 조금 더 고차원적인 Feature을 Detection해야할 때도 있다.

위의 사진에서 각각 key feature를 3개씩 뽑으라고 하면 다음과 같이 대답할 수 있다. 이런 과정은 크게 3가지 단계를 거쳐 발생한다.

Domain Knowledge -> Define Feature -> Detect feature to classify 순으로 이루어져야 한다.
하지만, 이런 과정을 모든 상황에서 적용할 수 있는 것은 아니다.
같은 물체라도 다른 시점에서 보거나, 크기가 다르거나, 일부 정보가 사라진 형태이거나, 빛의 정도가 다른 등 다양한 변수가 발생한다.

과연 우리는 계층적인 특징을 hand engineering 대신 데이터에서 바로 뽑아낼 수 있을까?
Learning Visual Features
Fully Connected Neural Network
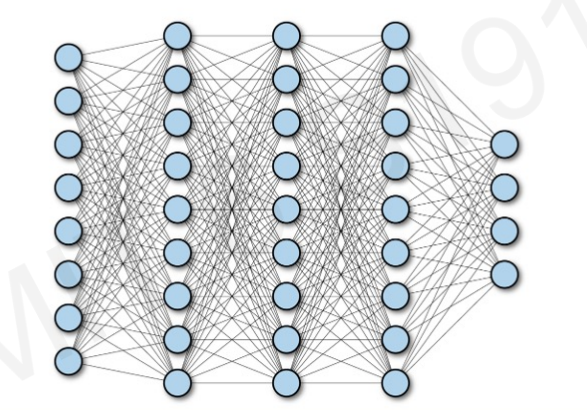
우리가 이때까지 살펴본 인공신경망의 구조는 위와 같이 Fully connected된 구조였다.
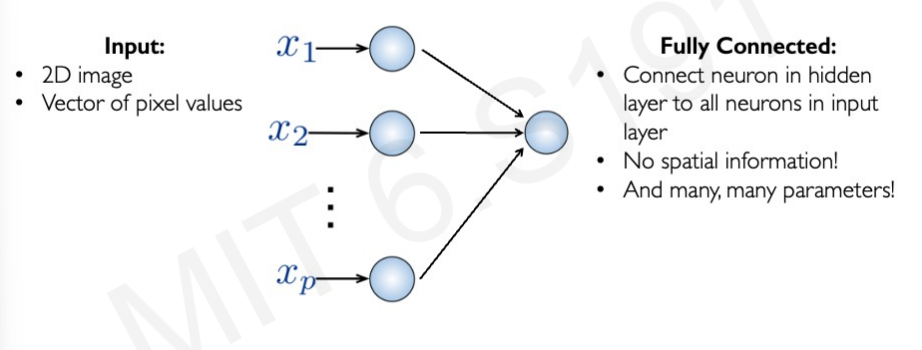
이를 바로 image에 적용하면 어떻게 될까?
이미지는 pixel 값의 vector로 한 이미지에 무수한 픽셀이 존재한다. Fully Connected되면 굉장히 파라미터가 많아진다. 그리고, 이미지는 서로 공간적인 특성도 가지고 있다. 하지만, 이 방식은 Spatial information이 존재하지 않는 문제점이 발생한다.
Using Spatial Structure
이미지의 공간적인 정보를 고려하기 위해 아래와 같은 방식으로 이미지의 일부분을 patch 형태로 잘라서 하나의 뉴런으로 전달하는 방식으로 hidden layer를 고안하는 방식이 탄생했다.
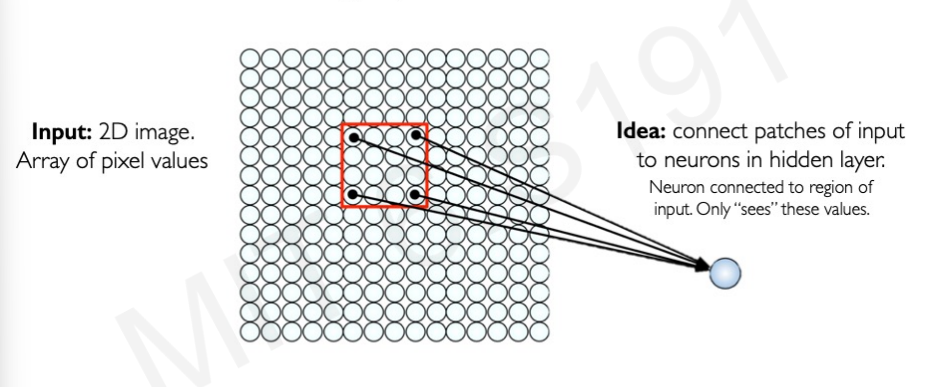
우리는 이렇게 patch 단위로 걔산하는 것을 convolution이라고 할 것이다.
Feature Extraction with Convolution
convolution으로 계산하는 방법은 아래와 같다.

1. filter라고 하는 weight 의 집합을 적용한다. 이것은 local feature을 추출한다.
2. 서로 다른 feature 을 추출하기 위해 여러개의 filter를 사용한다.
3. 각각의 filter의 파라미터를 공간적으로 공유한다.
Feature Extraction and Convolution : A Case Study
이제 개념적으로 말고 조금 더 실제적인 예시를 가지고 보겠다.

서로 모양이 다른 두 X가 있다고 하자. 이것을 이미지 pixel value로 표현하면 위와 같다. 우리는 두 X를 모두 같은 X로 판단하고 싶다.
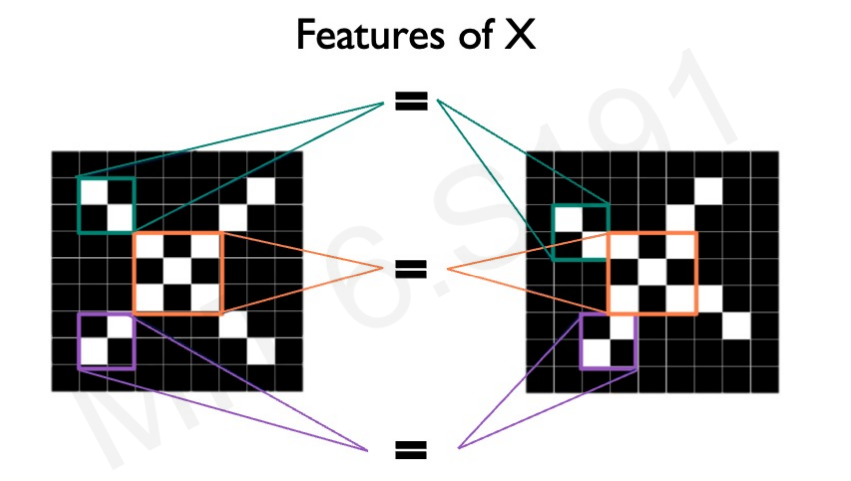
두 X의 feature을 살펴보면 일부부의 구성이 같다.(사진의 보라, 청록, 주황색)
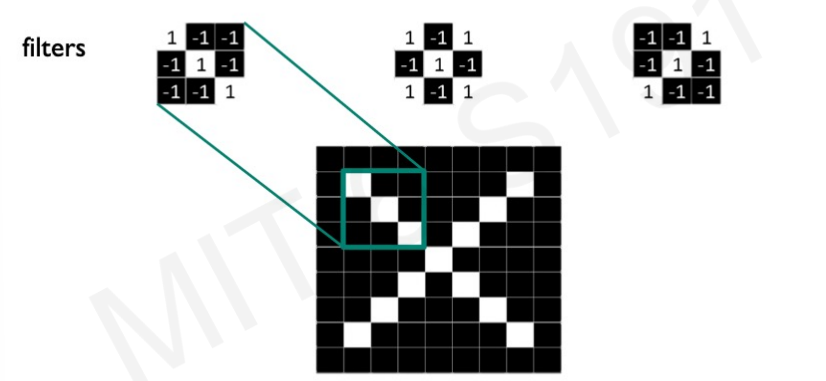
우리는 여러 Filter를 convolution operation을 이용해 특징을 추출해 두 개가 동일하다는 것을 파악할 수 있다.
The convolution operation
그럼 구체적으로 convolution operation은 어떻게 진행될까? 5X5 Image와 3X3 filter가 있다고 하자.
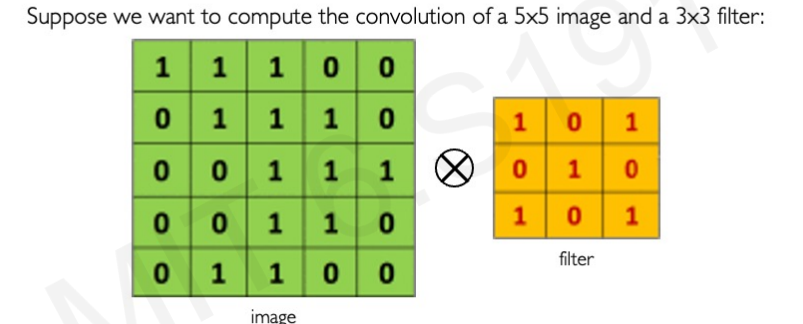
우리는 이를 element-wise multiply를 적용하여 계산하고 그에 따른 결과를 모두 합하여 한 pixel의 output으로 결정할 것이다.
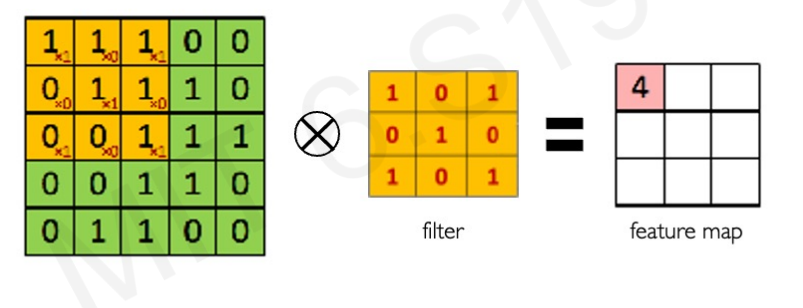
위와 같이 1과 0을 곱해 나온 값인 4가 첫번째 픽셀의 output이 된다.
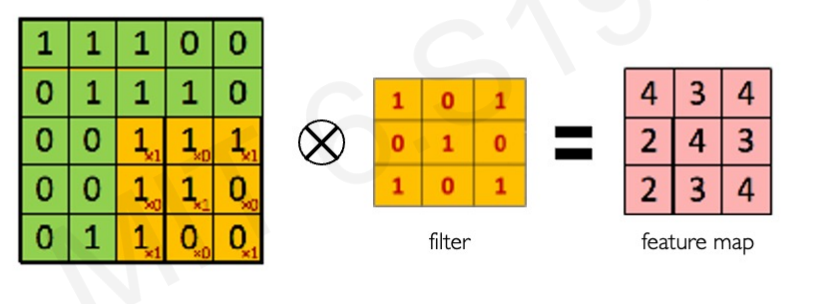
전체 계산 결과는 다음과 같다.
우리는 다양한 filter를 이용해 다양한 특징을 뽑아낼 수 있다.

어떻게 Filter의 값을 정하냐에 따라 이미지에서 강조되는 부분이 달라진다. 다양한 filter를 적용하여 여러 특징을 추출한 뒤 이를 한꺼번에 고려하면 더욱더 정확도가 높아질 수 있다.
Convolution Neural Networks
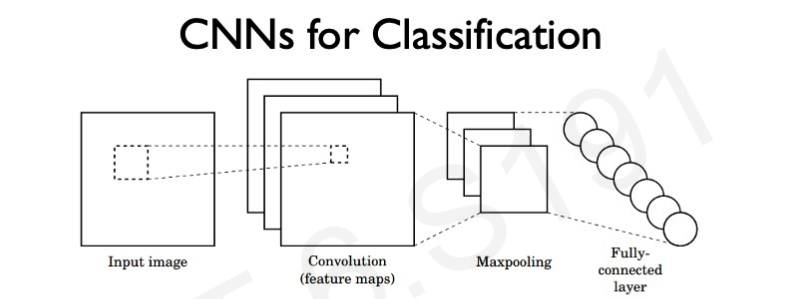
Classification을 위한 CNN은 크게 3가지 개념으로 구성되어 있다.
1. Convolution
2. Non-linearity
3. Pooling
각각의 개념을 자세히 살펴보자.
Convolutional Layers: Local Connectivity
convolution은 앞에서 계속 다루었던 개념으로 공간적 처리를 위해 도입되었다. (위에서 자세히 다루었으니 넘어가겠다)
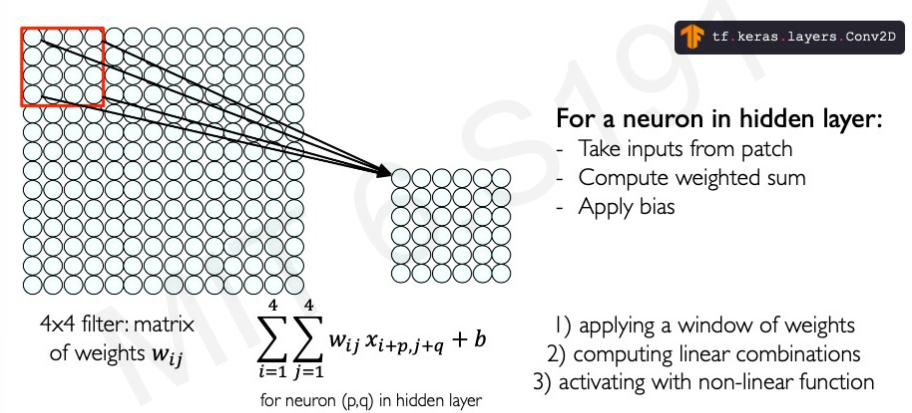
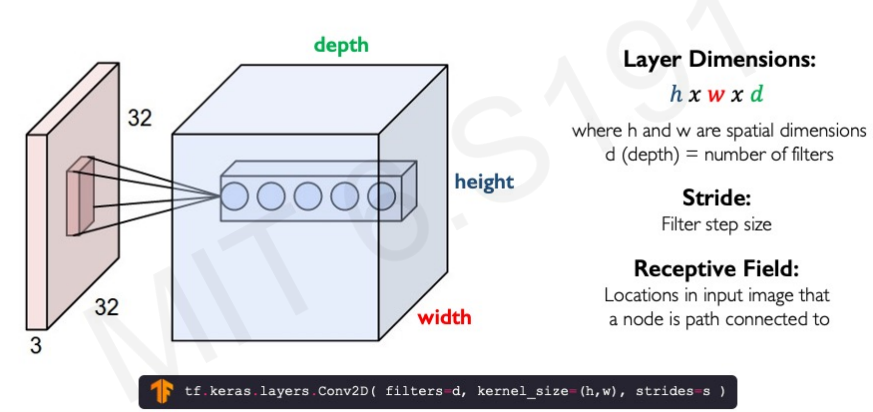
Spatial Arrangement of Output Volume
Layer Dimention은 hXwXd이다. 이 때 d는 filter의 개수이다. 여러 개의 filter를 사용하면 다양한 feature를 추출할 수 있다. 만약 사람 얼굴을 감지한다고 할 때 한 filter는 코를 추출하고 하나는 눈을 추출하고 하나는 코를 추출하는 방식으로 사용된다음 이것을 합치면 얼굴이 된다. 이런식으로 각각의 feature를 추출하기 위해 여러 filter를 사용한다.
Introducing Non-Linearity
Non-linearity도 굉장히 중요한 개념 중 하나라고 소개하고 있다. non-linearity한 대표적인 function 이 ReLU이다. non-linear을 적용하면 우리가 중요하게 생각하지 않는 Feature을 제거하여 볼 수 있다. 특히, ReLu의 경우 negative value를 zero로 변환하여 positive value에 더 집중할 수 있도록 해준다.

Pooling
pooling을 통해서는 image의 차원을 줄일 수 있다. 점점 깊어질 수록 pooling을 통해서 image 차원을 줄여준다. 그 이유는 convolutional layer를 통과하면서 결국은 하나의 neuron이 가지는 reception field 는 더 넓어지게 되고 filter의 dimensionality는 결과적으로 넓어지게 되기 때문이다.

Pooling은 Maxpooling이 가장 일반적으로 사용된다. Maxpooling은 정말 간단하게 해당 영역의 가장 큰 부분을 취하는 것이다.
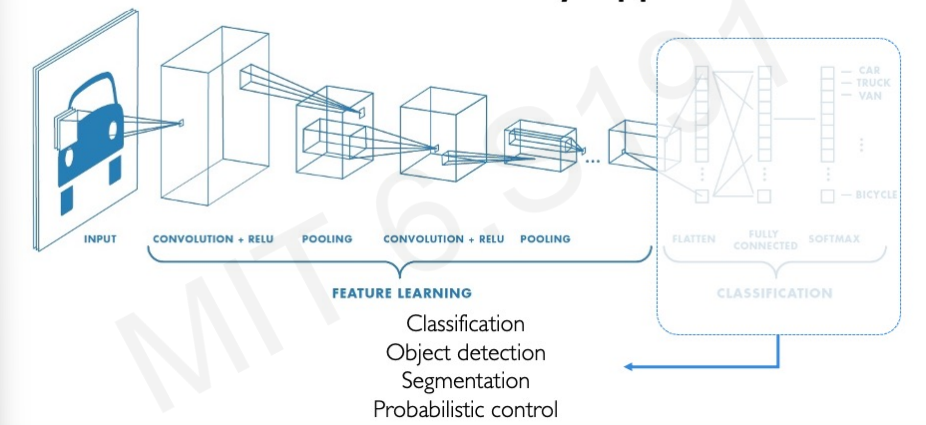
CNNs for Classification: Feature Learning
요약하자면 classification을 위한 CNN은 Feature Learning과 Classification 2부분으로 나눌 수 있다. 첫번째 부분에서 특징을 추출하고 그 특징을 이융해 classification을 하는 것이다.

Feature Learning 과정은 다음과 같다.
1. Learn Features in input image through convolution
2. Introduce non-linearity through activation function (real-world data is non-linear)
3. Reduce dimensionality and preserve spatial invariance with pooling
Classification은 다음과 같다.

End-to-end code example
import tensorflow as tf
def generate_model():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, filter_size=3, activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=2, strides=2),
tf.keras.layers.Conv2D(64, filter_size=3, activation='relu),
tf.keras.layers.MaxPool2D(pool_size=2, strides=2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(1024, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax)
])
return model
Applications
우리는 같은 구조를 이용해 다양하게 응용할 수 있다. 마지막 부분을 Classification, object detection 등 다양한 task로 변형시킬 수 있다.
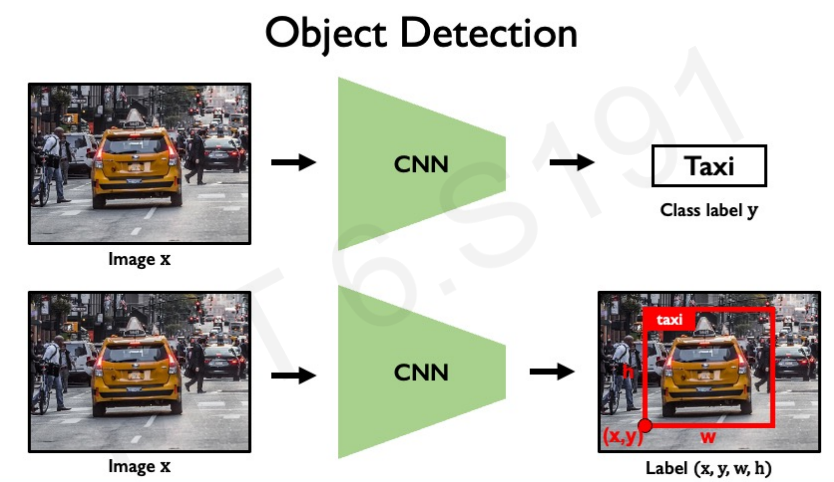
Object Detection
앞에서 계속 했던 image classification은 단순히 객체가 있냐 없냐를 나타내는 것이다. 지금부터 볼 object detection은 image에 object가 있는지에 대한 여부 뿐만 아니라 어디에 존재하는지까지 탐지하는 것을 의미한다. 보통 bounding box로 나타낸다.
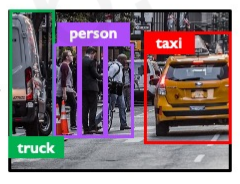
object detection은 object가 단일 일 때도 가능하지만, 여러개일 때 아래처럼 multi로 detect 하는 것이 가능하다.
하지만, Object Detection을 할 때 수백개의 bounding box를 그려 하나씩 물체를 대조해볼 수가 없다. 특히 최근 이미지는 해상도가 매우 높고 이런 이미지에는 적용불가능하다. 그래서 R-CNN이 등장하였다.
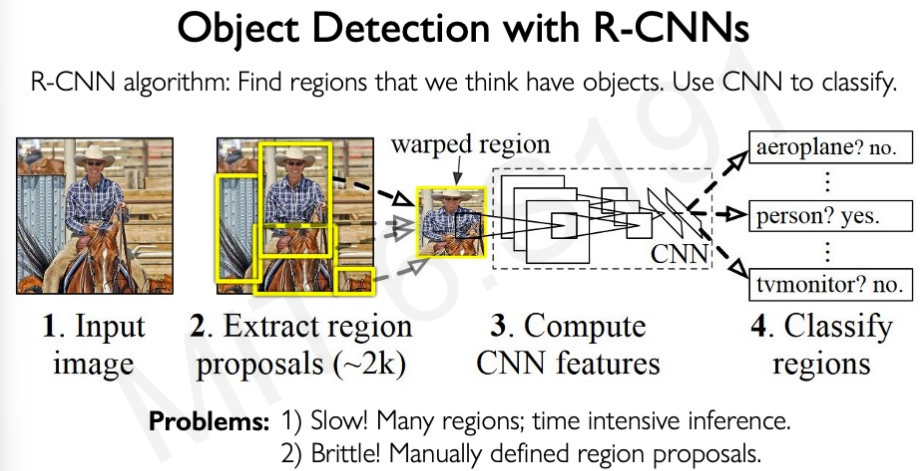
R-CNN은 object 가 있을 것 같은 의미있는 공간만 집중하여 특징을 추출하는 방식이다. 당연히 이 방식이 random box 방식보다 빠른 성능을 제공한다.
Faster R-CNN
R-CNN과 관련된 다양한 변형 모델들이 있고, 그 중 가장 유명한 Faster R-CNN에 대해 알아볼 것이다.
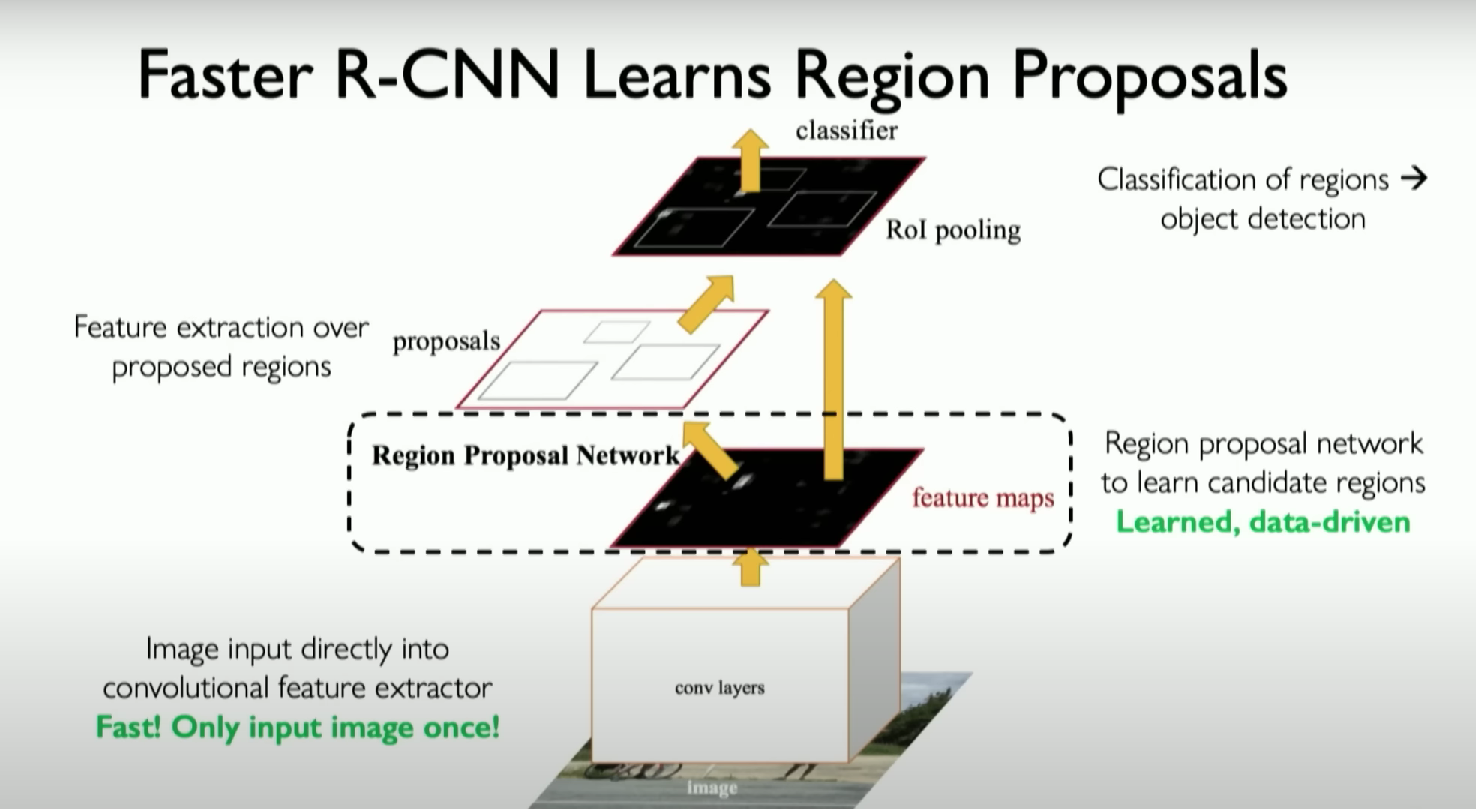
가장 중요한 특징은 주요한 특징이 있는 지역만 다음 단계로 보내는 것이다. 그 뒤에 각각의 지역이 무엇에 해당하는지 추출한다. 이것은 매우 빠르게 실행되기 때문에 실생활에서 가장 많이 쓰이는 모델이다.
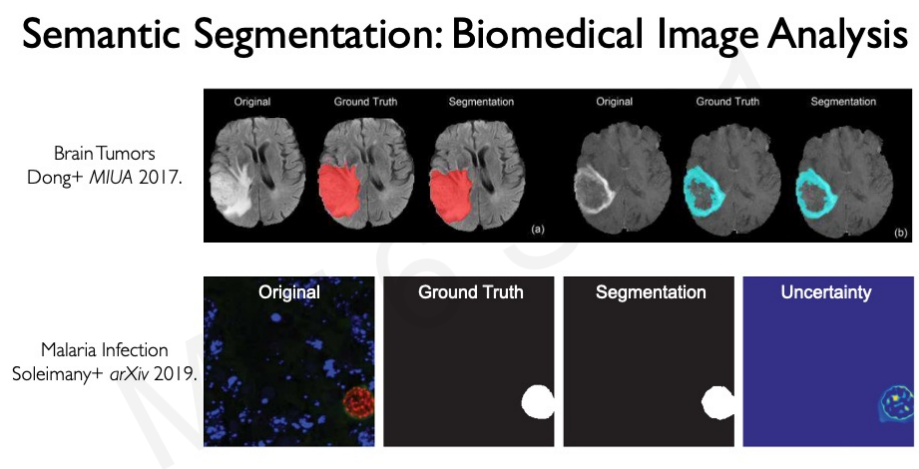
Semantic Segmenation
classification과 다르게 bounding box를 그리는 것이 아닌 각각의 픽셀 단위로 분류하는 것이 segmentation이다. 이렇게 하려면 모든 픽셀이 무엇을 의미하는지 분석할 필요가 있다.

전체 구조의 왼쪽은 encoder로 downscaling을 통해 새로운 공간으로 재구성한다. 그리고 이것을 upscaling을 통해 기능을 확장해 적용한다. 이것은 최근 굉장히 많은 분야에 적용되고 있다.

Summary
'Computer Science > AI' 카테고리의 다른 글
| [AI] 컴퓨터 비전 - 영역 분할 (고전적인 기법을 중심으로) (0) | 2024.04.21 |
|---|---|
| [AI] 컴퓨터비전 - 기초 영상 처리 기법 (1) | 2024.04.20 |
| [AI] Ensemble Learning - Voting, Bagging, Boosting, Random Forests (2) | 2023.10.17 |
| [MIT 6.S191] Recurrent Neural Networks, Transformers, and Attention (0) | 2023.09.27 |
| [MIT 6.S191] Introduction to Deep Learning (0) | 2023.09.13 |








