
[AI] 컴퓨터 비전 - 지역 특징 (모라벡, 해리스, SIFT)
https://m.hanbit.co.kr/store/books/book_view.html?p_code=B8870109394
IT CookBook, 컴퓨터 비전과 딥러닝
규칙 기반의 고전 컴퓨터 비전을 지원하는 OpenCV와 데이터 중심의 딥러닝 컴퓨터 비전을 지원하는 텐서플로를 활용한 85개 파이썬 프로그램으로 컴퓨터 비전을 균형 있게 배울 수 있습니다.
m.hanbit.co.kr
위 도서를 기반으로 정리한 내용이며, 일부 내용이 없거나 추가되었을 수 있습니다. 자세한 내용을 알고 싶으면 위 책을 참고하여 주세요.
5.1 지역 특징의 조건
- 반복성 : 같은 물체가 서로 다른 두 영상에 나타낫을 때 첫 번째 영상에서 검출된 특징점이 두 번째 영상에서도 같은 위치에 검출되어야한다.
- 불변성 : 물체에 이동, 회전, 스케일, 조명 변환이 일어나도 특징 기술자의 값은 비슷해야한다.
- 분별력 : 물체의 다른 고셍서 추출된 특징과 두드러지게 달라야한다.
- 지역성 : 작은 영역을 중신으로 특징 벡터를 추출해야한다. ( = 가림이 발생해도 안정적인 매칭이 가능함 )
- 적당한 양 : 특징 점이 너무 많으면 계산 시간이 과다해지고, 너무 적으면 오류에
- 계산 효율 : 계산 시간이 매우 중요한 응용이 많기 때문에 효율이 좋아야한다.
5.2 이동과 회전에 불변한 지역 특징
모라벡 알고리즘
대응점을 찾기 위하여 영상의 일부를 보여주었을 때 색의 변화가 가장 큰 곳은 대응점을 쉽게 찾을 수 있다. 반면에 색의 변화가 적은 곳은 대응점을 찾기가 어렵다.

모라백은 이 성질을 적용하여 찾기 좋은 성질을 제곱차의 합을 이용하여 아래 식을 제안하였다.
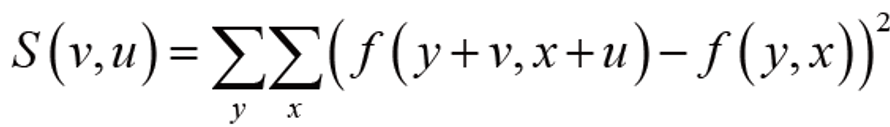
이때, v, u는 (-1,0,1) 을 선택한다. 그럼 S(v, u)는 9가지 경우의 수가 발생한다. 이를 3x3으로 배치하여 표현한다.
책에서 주어진 예제를 계산해보면서 위의 식을 자세히 알아보겠다.
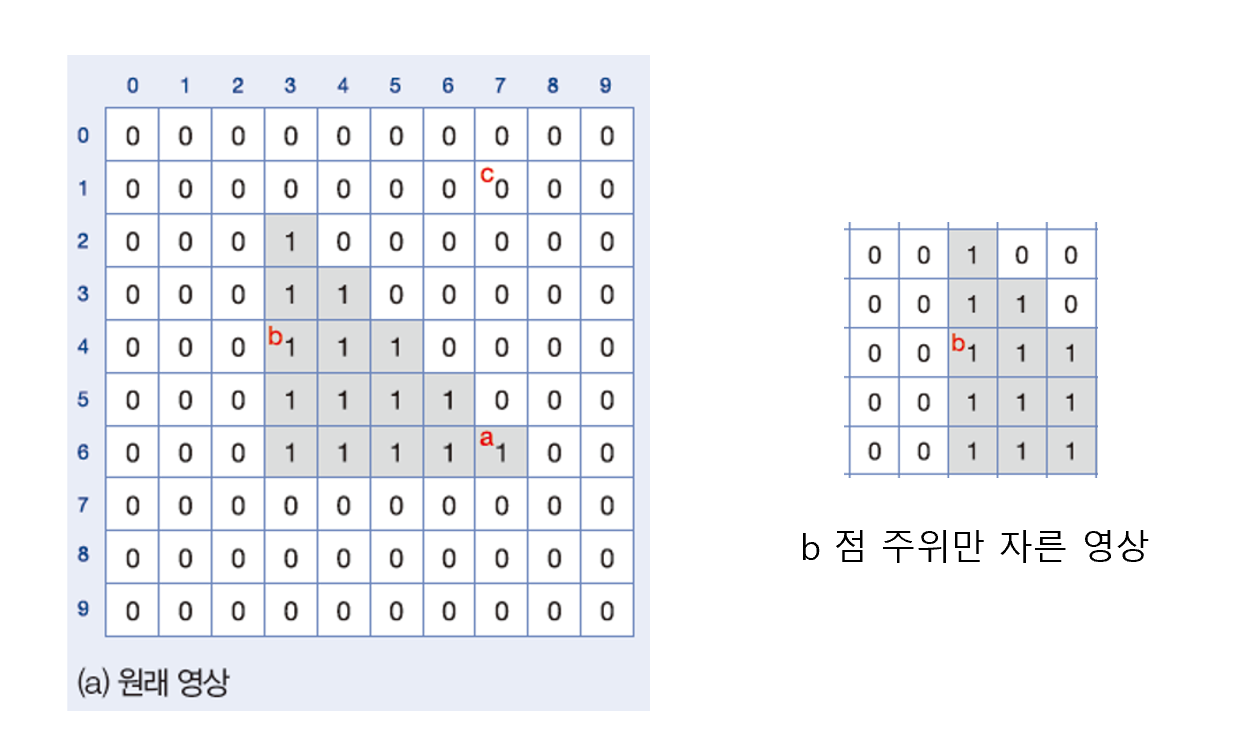
a, b, c 세 개의 점이 표시되어 있는데 b로 계산해보겠다. b는 (y, x) = (4, 3)이며 계산할 때 편의를 위해 b 점 주위만 자른 영상으로 설명하겠다. (실제 계산은 자르지 않는다)
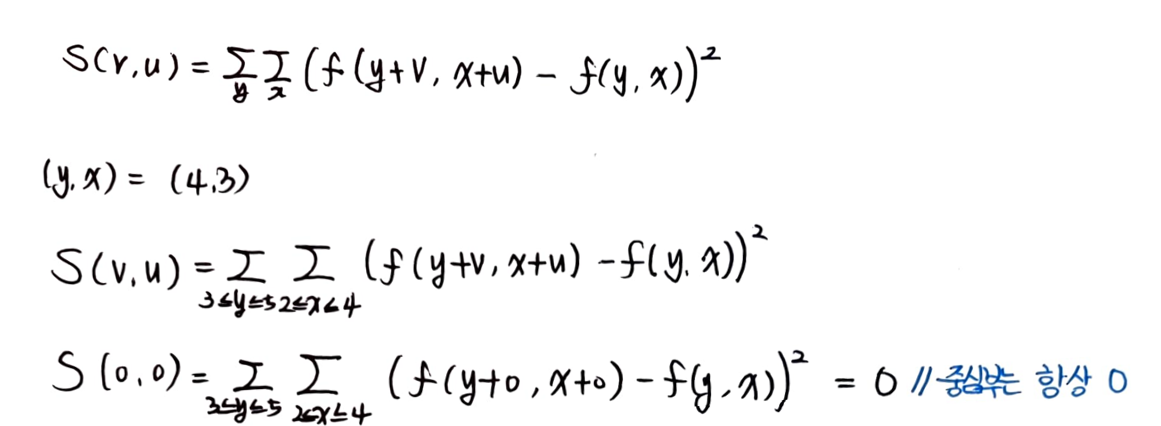
S(4,3) 에 따라 x, y의 값을 제한하고, S(0,0)을 계산하였다. S(0,0)은 값이 y, x의 값이 무엇인지와 관련없이 항상 0이 나온다는 것을 알 수 있다.
그 다음 S(0,1), S(-1,1)을 차례대로 구해보자
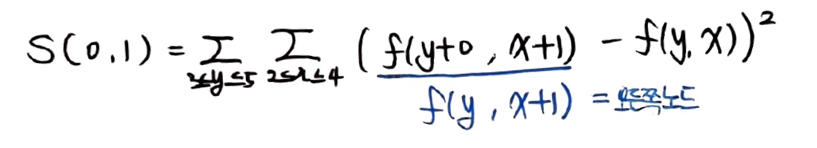
S(0,1) 식을 정리하면 위와 같은 결과가 나온다. 그리고 f(y, x+1)은 해당위치보다 한칸 오른쪽 화소를 의미한다. 그래서 오른쪽 값에서 현재 위치의 값을 뺀다음 제곱한 것의 합을 구하면 된다.
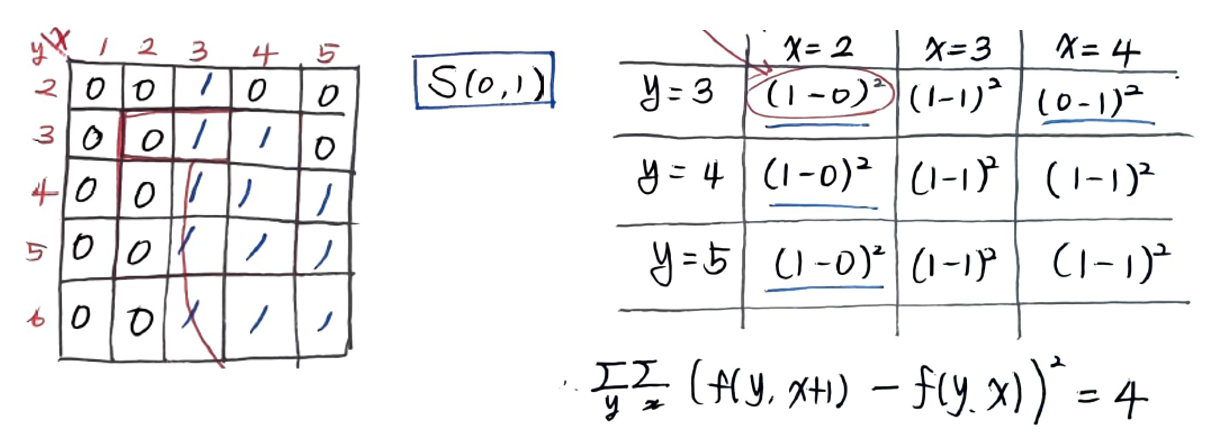
계산 과정을 표로 나타낸 다음 합을 구하면 위와 같다. 동일한 방법으로 S(-1,1)도 구할 수 있다. f(y-1, x+1)은 오른쪽 위의 화소와 같다.

이 S들의 계산 결과는 3x3 S 맵에 저장해둔다.
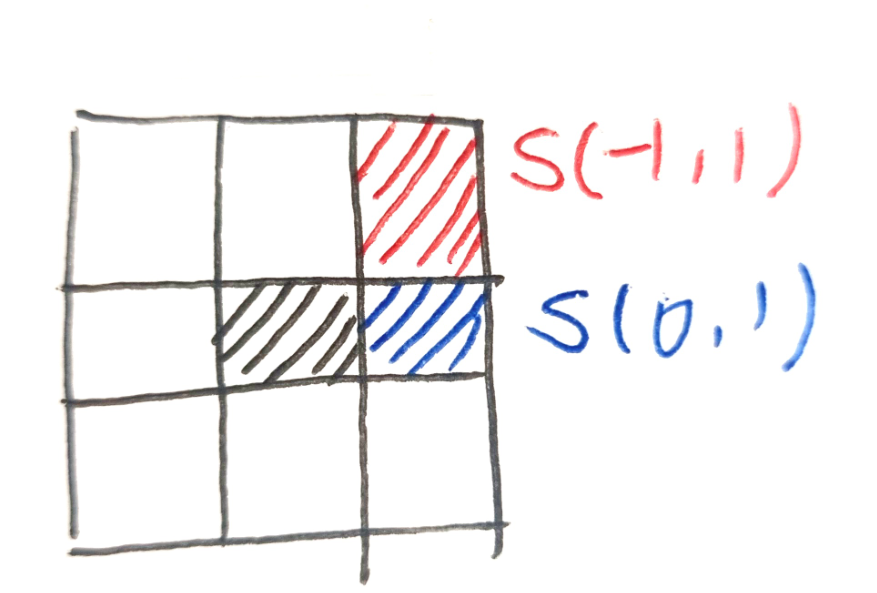
저장 위치는 차를 계산할 때 상대 위치에 있던 화소의 위치와 같다. ( S(0,1)은 오른쪽 화소 - 현재 화소 의 합이었고 저장도 오른쪽 화소에 한다는 의미 )
이와 같은 방식으로 a,b,c를 모두 계산하면 다음과 같다.
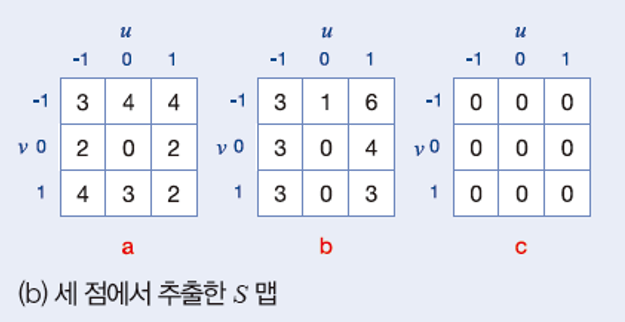
이를 분석해보면, 변화가 없는 c는 모든 값이 0이 나왔다. 즉, 지역특징으로 사용할 수 없다. b는 상대적으로 좌우는 특징이 뚜렷하나 상하는 특징이 없다. a는 모든 위치에서 특징이 뚜렷하기 때문에 지역특징으로 사용하기 가장 적합하다.
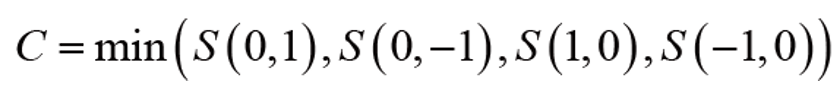
이렇게 상, 하, 좌, 우의 S 값을 구해서 최소인 값을 특징 가능성 값 C로 취한다.
해리스 특징점
모라벡 알고리즘은 현실적이지가 않다는 단점이 있다. 실제 세계의 영상은 작은 마스크를 이용해 상하좌우 이웃만 보는 방법으로는 한계가 있다. 해리스는 가우시안을 적용해 알고리즘을 개선한다.
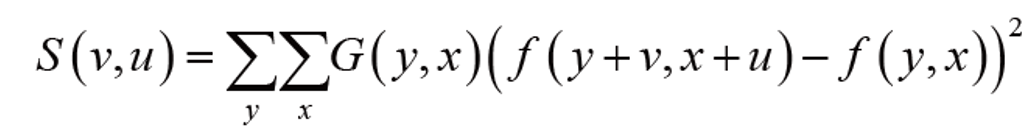
모라벡 알고리즘에 G(y,x)를 적용했다.
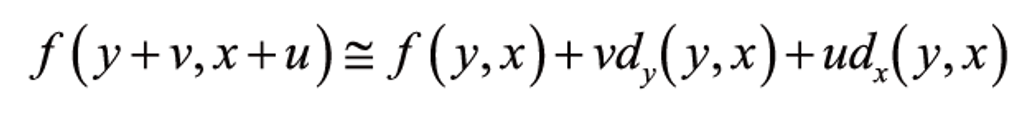
테일러 확장에 따라 위 식이 성립하기 때문에 식을 아래와 같이 변환할 수 있다.
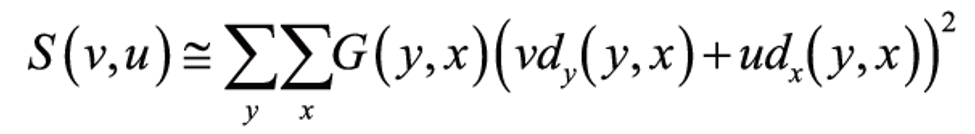
우리는 이 표현을 행렬 표현으로 정리해보겠다.
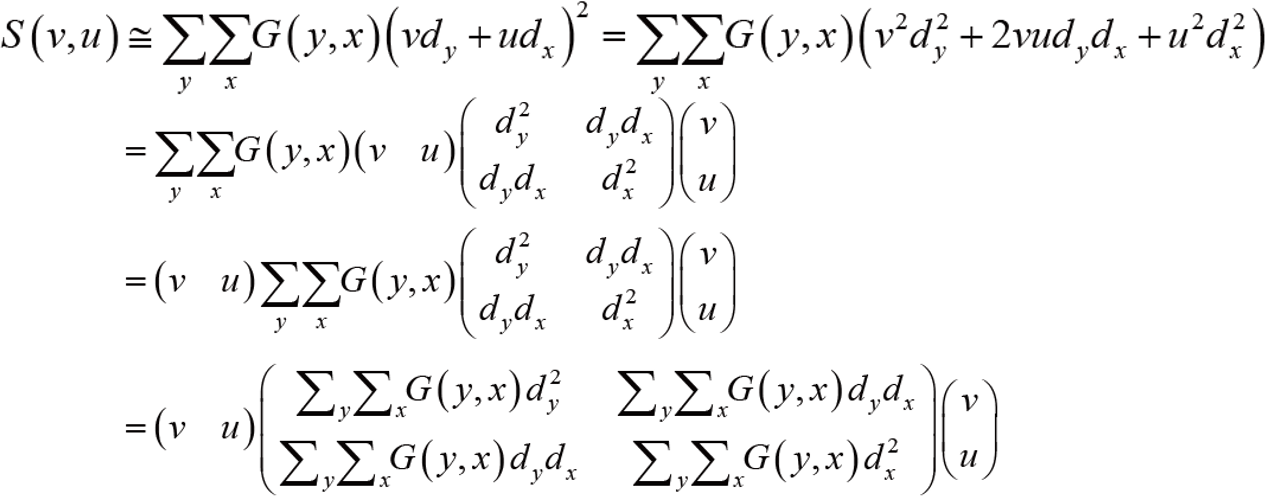
여기서 컨볼루션 연산의 형태는 컼볼루션 연산자를 이용해 변환하면 최종적으로 아래 식으로 변환할 수 있다.
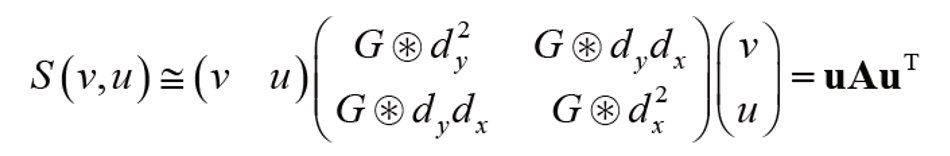
이 때, A에 해당하는 행렬을 우리는 2차 모멘트 행렬이라고 부른다.
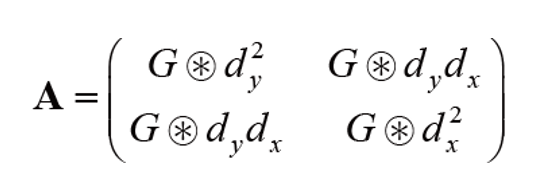
A는 유용한 특성이 있다.
1. 정수 뿐 아니라 실수도 계산 가능하다.
2. 어떤 화소 주위의 영상 구조도 표현하고 있어 A만 분석하면 지역 특징 여부를 판단할 수 있다.
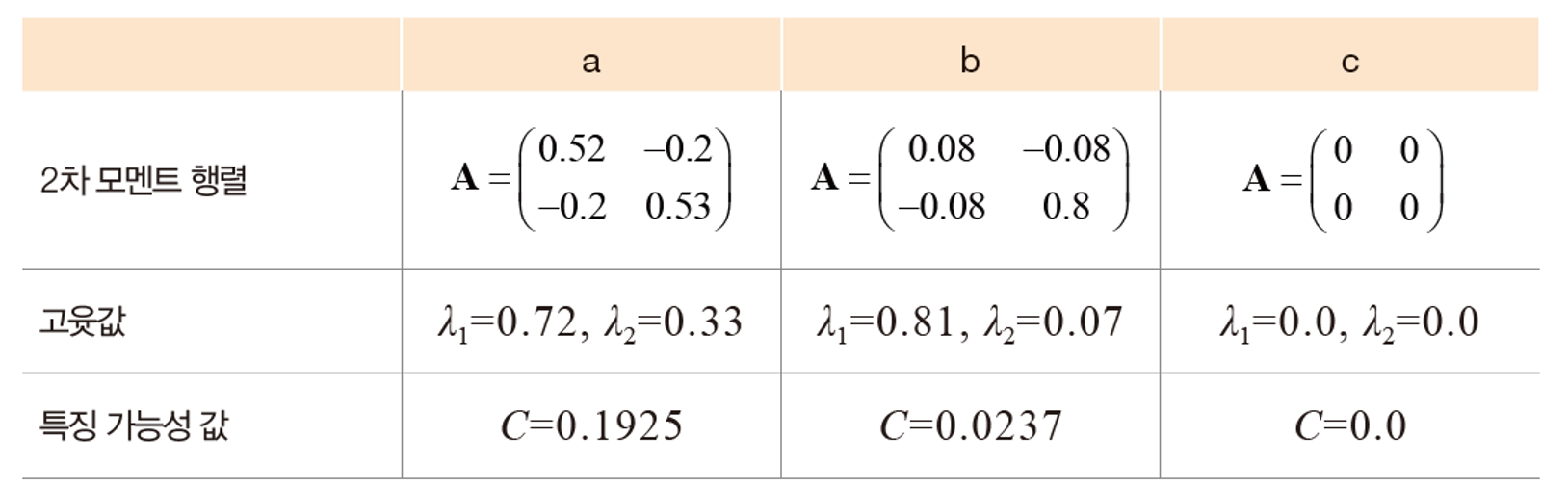
위 예제의 a,b,c도 해당 과정을 계산해 2차 모멘트 행렬을 구하고 해당 행렬의 eigenvalue를 구할 수 있다. 우리는 이 고윳값을 아래 식에 적용해 특징 가능성 값을 구할 수 있다.
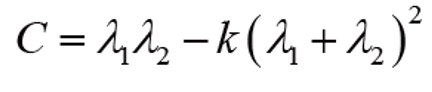
하지만, 화소가 많으면 고윳값을 계산하는 시간도 줄이는 것이 좋으니, 아래 식으로 빠르게 계산한다.
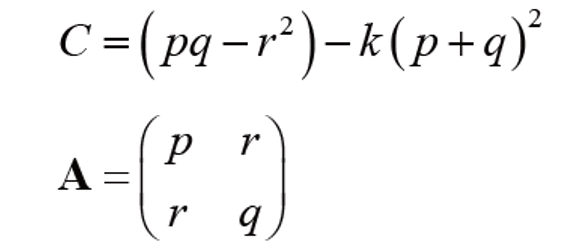
이런 해리스 알고리즘은 이동과 회전에는 불변하나 스케일에는 불변하지 않는다.
5.3 스케일에 불변한 지역 특징
스케일 공간 이론은 스케일을 모르는 상황을 대응하기 위한 세 단계 전략을 세웠다.
1. 입력 영상 f로부터 다중 스케일 영상을 구성한다.
2. 구성한 다중 스케일 영상에 적절한 미분 연산을 적용하여 다중 스케일 미분영상을 구한다.
3. 다중 스케일 미분영상에서 극점을 찾아 특징점으로 취한다.
1번은 거리가 멀어지면 세부 내용이 흐려지는 것을 모방하였다. 표준편차를 키우면서 가우시안 필터로 스무딩하여 흐려지는 것을 표현한다. 2번은 거리가 멀어지면 크기가 작아지는 것을 모방하였다. 이 것을 실현하기 위해 피라미드 영상으로 시뮬레이션 한다.
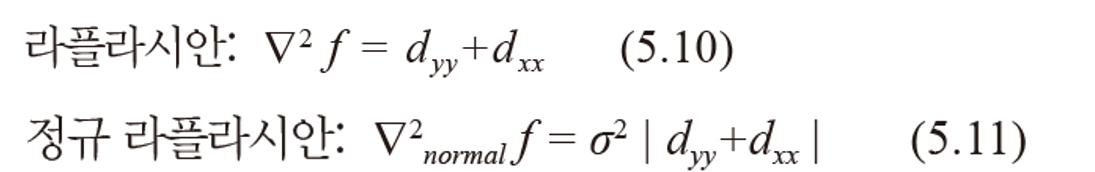
5.4 SIFT
Scale-Invariant Feature Transform은 스케일에 불변한 지역 특징을 추출하기 위해 고안된 방식 중 가장 성공한 방식이다.
SIFT 검출
5.3에서 소개한 알고리즘의 변형이기에 위 과정을 따라간다.
1. 다중 스케일 영상 구축
가우시안 스무딩과 피라미드 방법을 결합하여 다중 스케일 영상을 구축한다.
2. 다중 스케일 영상에 미분 적용
정규 라플라시안을 사용하는 것이 시간 소요가 커서 유사한 DOG(Difference Of Gaussian) 을 사용한다. 이웃한 가우시안을 빼면 때문에 연산이 매우 빠르다.
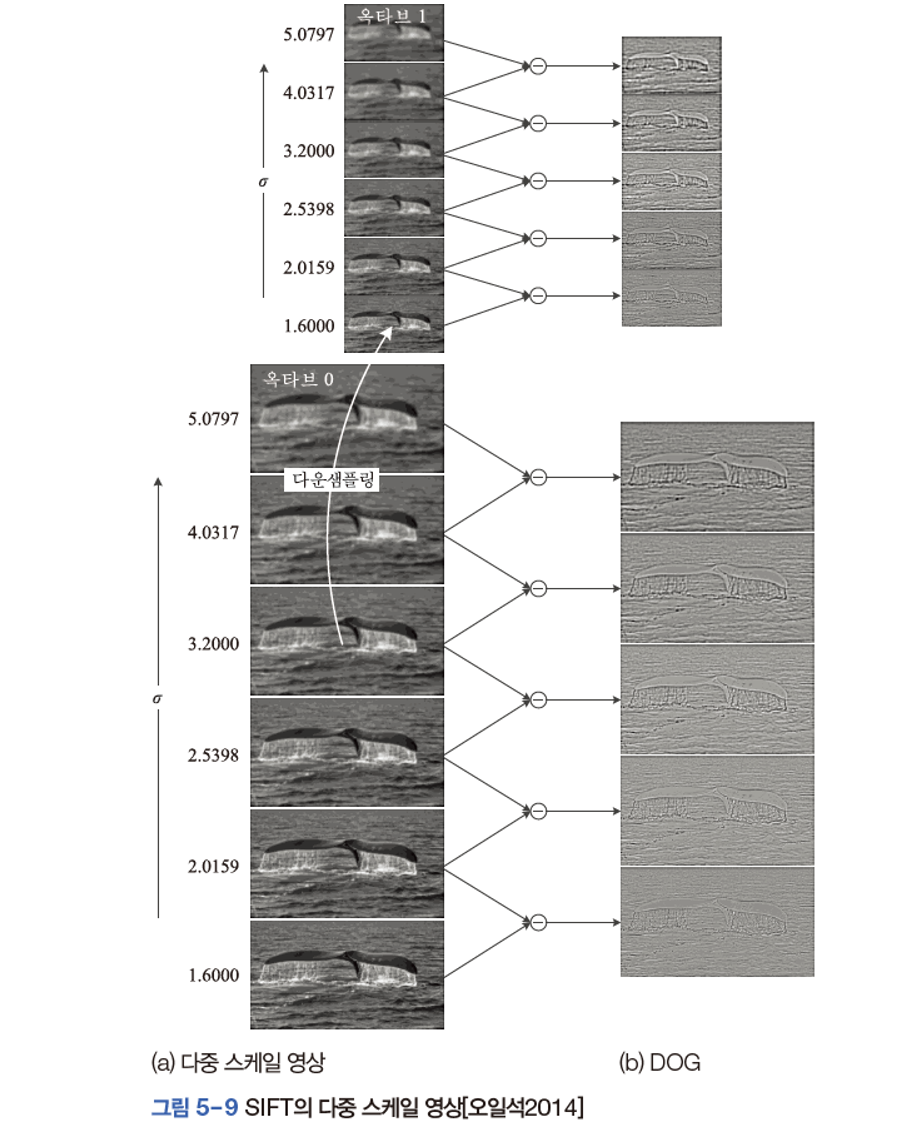
3. 극점 검출
DOG 에서 3차원 비최대 억제를 적용한다. 본인 주위의 8-이웃과 i-1, i+1번째 DOG의 각 9개의 화소 즉, 총 8 + 9+ 9 = 24개의 화소에 비최대 억제를 적용하여 계산한다.
우리는 이렇게 찾아낸 특징점을 (y, x, o, i) 로 표현한다.
SIFT 기술자
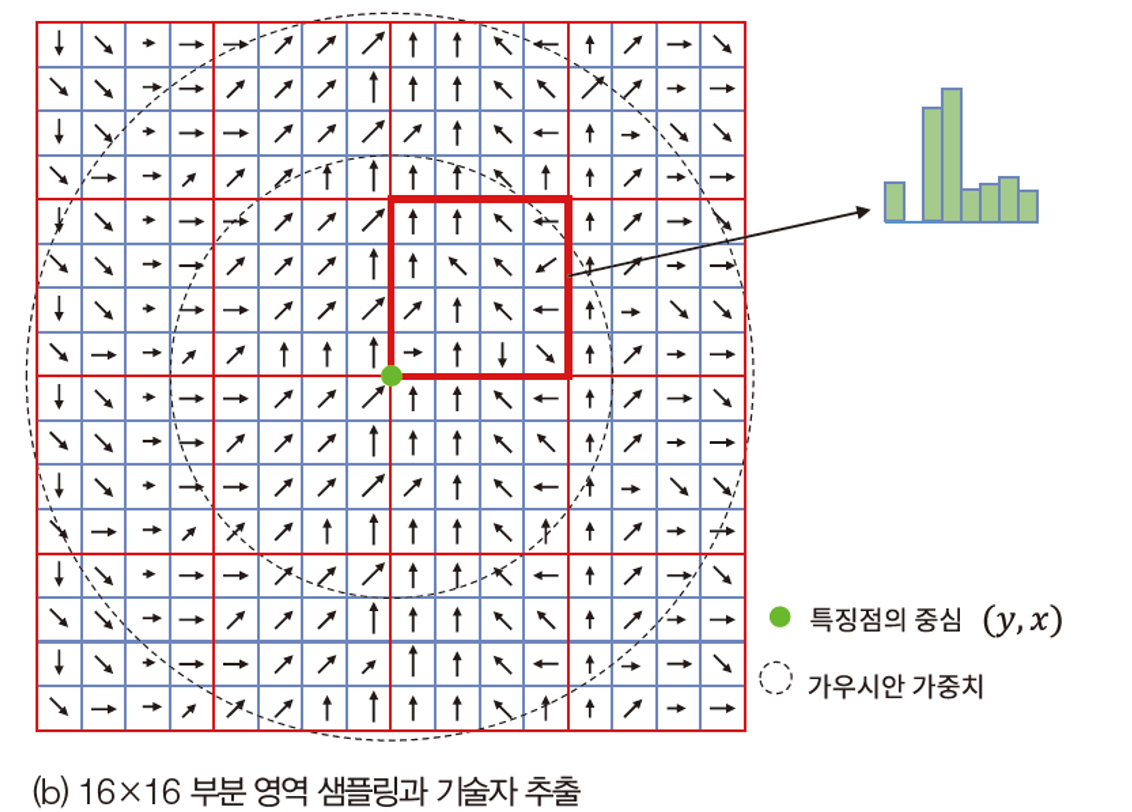
특징점만 사용하기에는 물체를 매칭할 수 없기 때문에 주위를 살펴 풍부한 정보를 가진 기술자를 추출한다.
1. o와 i로 가장 가까운 가우시안을 결정하고 기술자를 추출하여 스케일 불변성을 달성한다.
2. 기준 방향을 정하고 기준 방향을 중심으로 특징을 추출하여 회전 불변성을 달성한다.
3. 기술자 x를 단위벡터로 바꿔 조명 불변성을 달성한다.
최종 추출된 기술자를 포함하여 특징점을 ( y, x, σ, x ) 로 표현하고, x 는 16x8의 128차원을 가지고 있다.
5.5 매칭
추출된 특징점을 어떻게 매칭할 수 있을까? 특히 잡음이 섞인 기술자가 있다면 더욱 어려워진다.
매칭 전략
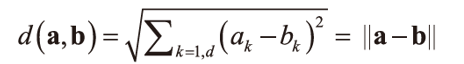
1. 고정 임계값
두 기술자의 거리를 계산해 고정 임계값보다 작은 기술자를 매칭으로 간주함. 즉, 아래 식을 만족하는 모든 값을
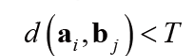
2. 최근접 이웃
a는 가장 가까운 b를 찾아 위 식을 만족하면 매칭 쌍으로 간주함.
3. 최근접 이웃 거리 비율
점 a는 거리가 가장 가까운 bj와 두번째로 가까운 bk를 찾아 bj와 bk가 아래 식을 만족하면 매칭함.
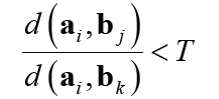
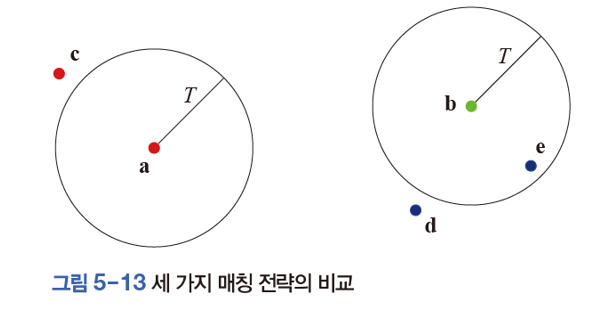
위 그림으로 세 가지 매칭 전략을 비교하면, 1, 2번 방식은 b-e 쌍을 찾는다. (거짓 긍정) 3번 방식은 a를 기준으로 봤을 때, a=c와 a-d의 비율이 T보다 작기 때문에 a-c를 이웃으로 본다. (참 긍정) 반대로 b-e는 b-d과의 비율이 T를 넘기 때문에 거짓으로 판별한다. (참 부정)
위의 상황에서 알 수 있듯이 3번 방식이 가장 정확한 결과를 내고 있다. 실제로 많은 연구에서 3번이 가장 좋음을 밝혀냈다.
매칭 성능 측정
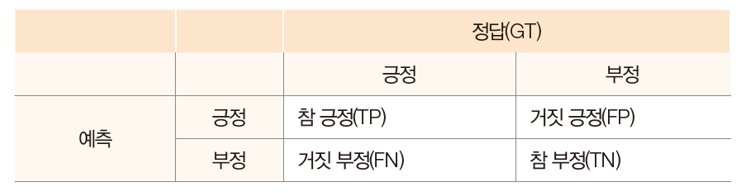
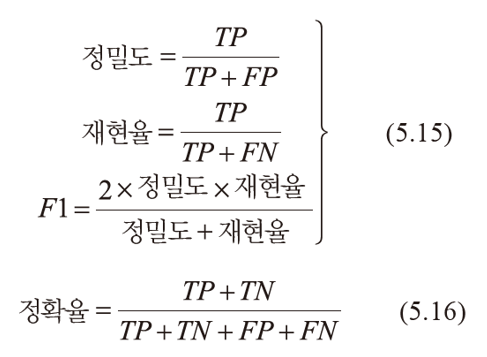
ROC : Receiver Operating Characteristic

위 식에서 T를 작게하면 거짓 긍정률은 작아지고 T를 크게 하면 거짓 긍정률은 커지지만 참 긍정률도 함께 커진다.
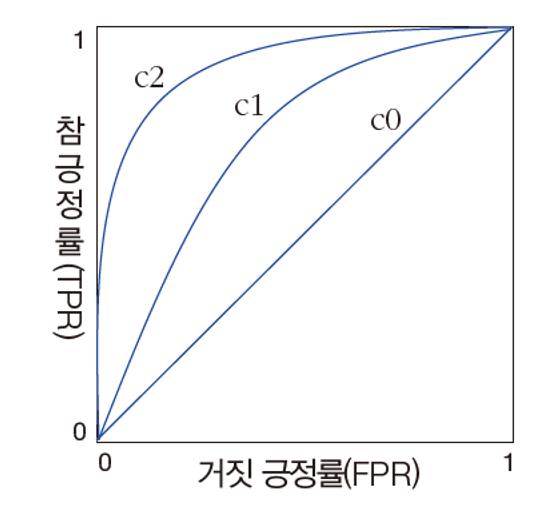
위 곡선을 ROC라고 하며 ROC 아래의 면적이 AUC라고 한다.
빠른 매칭
속도라는 성능 지표는 실시간 응용에서 양보할 수 없는 강한 조건이다. 컴퓨터과학에서 성능을 위한 자료 구조는 BST와 해싱이 있다. 하지만, 특징점 매칭은 여러 값으로 구성된 특징 벡터이기 때문에 이를 바로 적용할 수 없어 새로운 자료구조를 고안해냈다.
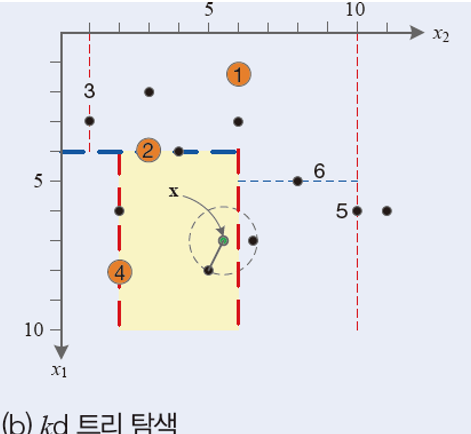
(1) kd 트리
1. 각 축의 분산을 구해 분산이 더 큰 축을 고른다.
2. 고른 축을 기준으로 중앙값을 찾아 Xleft, Xright로 분할한다.
3. 루트 노드에 중앙값을 배열하고 어떤 축을 기준으로 분할했는지에 대한 정보를 기록한다.
4. Xleft와 Xright 각각에 대해 같은 과정을 재귀적으로 반복한다.
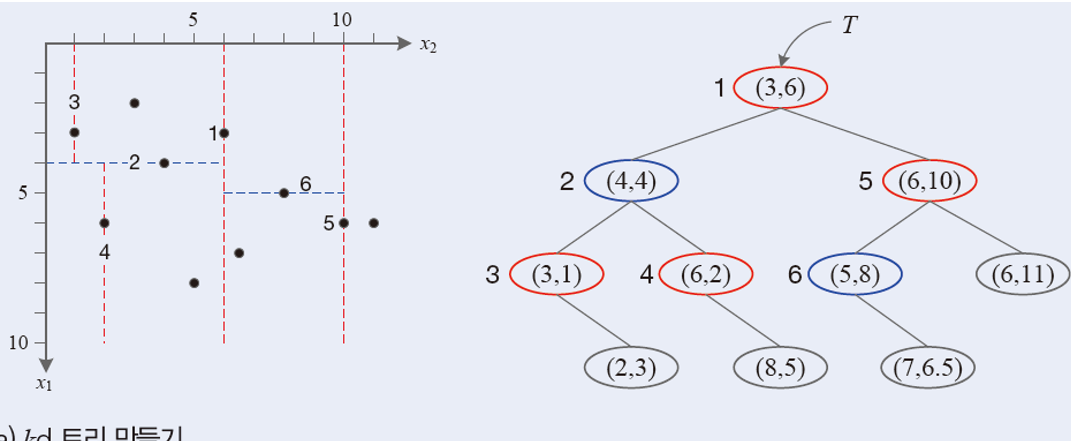
새로운 벡터 x = (7, 5.5) 가 입력되면 아래와 같은 결과가 나타난다.
(2) 위치 의존 해싱
위치 의존 해싱은 일반 해싱과 달리 비슷한 특징 벡터를 같은 칸에 담는다.
'Computer Science > AI' 카테고리의 다른 글
| [3DGS] gaussian function - N-dim gaussian (0) | 2025.02.07 |
|---|---|
| [3DGS] Gaussian function - 1D gaussian (0) | 2025.02.07 |
| [AI] 컴퓨터 비전 - 영역 분할 (고전적인 기법을 중심으로) (0) | 2024.04.21 |
| [AI] 컴퓨터비전 - 기초 영상 처리 기법 (1) | 2024.04.20 |
| [MIT 6.S191] Convolutional Neural Networks (1) | 2024.02.08 |








