
[3DGS] LangSplat: 3D Language Gaussian Splatting / brief version
Paper Information
- Title : LangSplat: 3D Language Gaussian Splatting
- Journal : CVPR 2024
- Author : Qin, Minghan, et al.

LangSplat: 3D Language Gaussian Splatting
Human lives in a 3D world and commonly uses natural language to interact with a 3D scene. Modeling a 3D language field to support open-ended language queries in 3D has gained increasing attention recently. This paper introduces LangSplat, which constructs
langsplat.github.io
Abstract
Problem
- ground CLIP langauge embeddings in a NeRF : cost ↑
- struggle with imprecise and vague 3D language fields
=> fail to discern clear boundaries between objects
Method: LangSplat
Details :
- scene-wise language autoencoder
- language features on the scene-specific latent space
- hierarchicaal semantics using SAM
Results:
- Ourperforms the previous SOTA method LERF
- 199x speed up compared to LERF
Proposed Approach
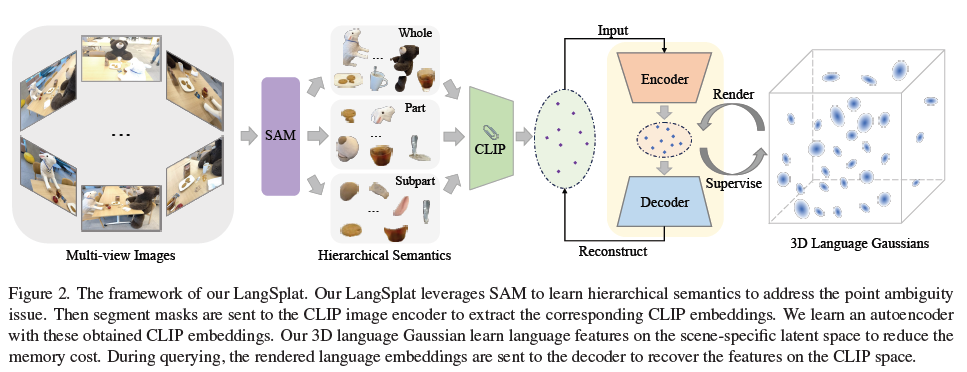
3.1. Revisiting the Challenges of Language Fields
Challenges 1. CLIP embedding
CLIP embeddings : image-aligned ( we need pixel=aligned )
=> point ambiguity problem
To address point ambiguity, most methods use a hierarchy of CLIP features from cropped image
=> imprecise, requiring simultineous rendering
Challenges 2. NeRF
time-consuming rendering process
=> not achieving real-time renderinng in high-resolution
3.2. Learning Hierarchical Semantics with SAM
Like SAM, this paper use the semantic hierarchy of objects in 3D scenes.
1. feed a regular grid of 32 x 32 point prompts into SAM to obtain the masks under three different semantic levels
2. remove redundant masks for each of the three mask sets
3. performs a comprehensive full-image segmentation based on its respective semantic level
Mathematically, the obtained pixel-aligned language embeddings are:
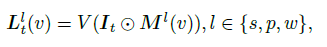
3.3. 3D Gaussian Splatting for Language Fields
Language embeddings on a set of 2D images
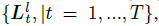
Original 3D Gaussians
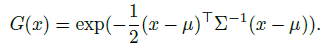
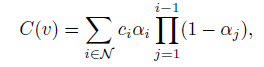
3D Language Gaussian
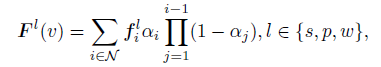
- s : subpart, p: part, w : whole (captured the ierarchical semantics provided by SAM)
- F^l(v) : represents the language embedding rendered at pixel v with the semantic level l
Scene-wise language autoencoder
Because CLIP features increase the memory requirements for storing 3D gaussians, this paper adopt autoencoder.
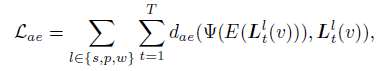
- encoder E : D-dimentional CLIPfeatures L^l_t to H^l_t
- decoder Ψ : reconstruct original CLIP embeddings from the compressed representation
- d_ae : a distance function usedfor the autoencoder
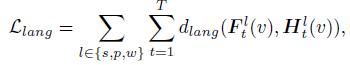
- L_lang : the distance function used for 3D language Gaussians
=> This approach not only preserves the rendering efficiency of Gaussian Splatting but also mitigates the catastrophic memory explosion associated with explicit modeling.
3.4. Open-vocabulary querying
3D language field can support open-vocabulary querying
follow the strategy used in LERF and choose the semantic level that yields the highest relevancy score
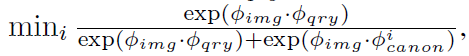
This method filters out points with relevancy scores lower than a chosen threshold, and predict the object masks with remainting regions
4. Experiments
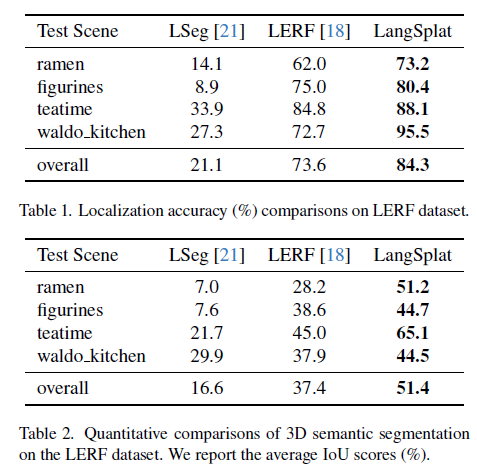

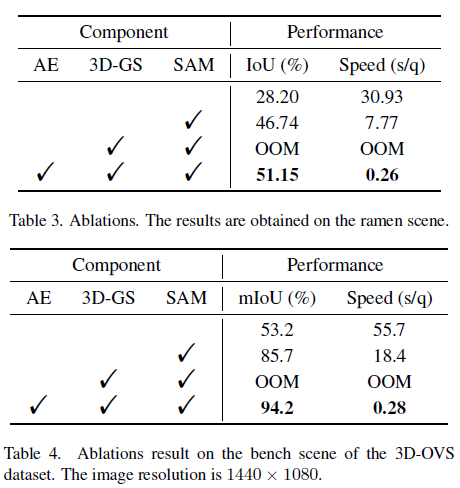

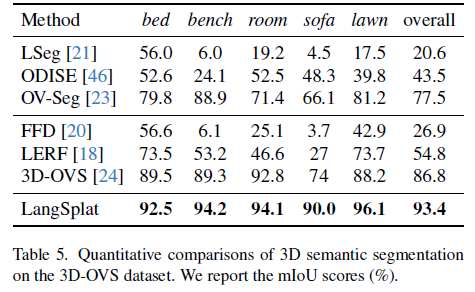
5. Conclusion
LangSplat : a method for constructing 3D lanauge fields athhat enables precise and efficient open-vocabulary querying within 3D spaces.
- 3D Gaussian Splatting with langauge featrues
- scene-specific language autoencoder
- hierarchy defined by SAM => solve the pointambiguity problem
The experimental results clearly demonstrate LangSplat’s superiority over existing SOTA methods like LERF, particularly in terms of its remarkable 199 × speed improvement and enhanced performance in open-ended 3D language query tasks.








