
[Video Compression] Plug-and-Play Versatile Compressed Video Enhancement
https://arxiv.org/abs/2504.15380
Plug-and-Play Versatile Compressed Video Enhancement
As a widely adopted technique in data transmission, video compression effectively reduces the size of files, making it possible for real-time cloud computing. However, it comes at the cost of visual quality, posing challenges to the robustness of downstrea
arxiv.org
1. Introduction
Video : The most popular multimedia formats
bandwidth constraints during transmission, (compressed with varying levels)
=> resulting in poor visual quality and suboptimal performance in downstream task
Previous methods
=> limited improvement... (neglects downstream tasks in real-world scenario.)
A favorable solution
=> codec-aware enhancement framework (Fig.1)

Key technique
- compression-aware adaptation (CAA) network
- Bitstream-aware enhancement (BAE) network
Contributions
- present a codec-aware framework for versatile compressed video enhancement
- develop a compression-aware adaptation network and a bitstream-aware enhancement
- experimental results show the superiority of this method over existing enhancement methods
2. Related Work
2.1. Compressed Video Enhancement
1) in-loop methods : embed filter in the encoding and decoding loops
=> not suitable for enhancing already compressed videos
2) post-processing methods : place filter at the decoder side
- MFQE / MFQE 2.0 : Use PQF detectors (SVM/BiLSTM)
- STDF : Handles inaccurate optical flow via spatio-temporal deformable convolution
- S2SVR : Models long-range dependencies using sequence-to-sequence learning.
However, most of these methods:
- Require separate models for each compression level, limiting adaptability.
- Focus only on I/P-frames.
Our approach introduces a hierarchical adaptation mechanism to handle all frame types and varied compression levels within a unified model.
2.2. Codec-Aware Video Super-Resolution
Recent VSR methods incorporate codec information (e.g., motion vectors, spatial priors) to enhance reconstruction:
- COMISR : Reduces warping errors from intra-frame randomness.
- Chen et al. : Use motion vectors to enhance temporal consistency and suppress artifacts.
- CVCP : Employs soft alignment and spatial feature transformation guided by codec data.
- CIAF : Leverages motion vectors and residuals to model temporal relations and reduce computation.
However, these methods are task-specific (only for VSR). They do not generalize to broader downstream tasks.
Our framework not only achieves competitive results in VSR, but also effectively supports diverse vision tasks such as optical flow estimation and object segmentation, demonstrating broader applicability.
2.3. Dynamic Neural Networks
Dynamic neural networks adapt parameters or structure per input to avoid separate models:
- MoE: Parallel branches selectively activated for weighted outputs.
- Dynamic Parameter Ensemble: Fuse preset expert layers’ parameters for better generalization.
- Gain-tune: Predicts channel-wise scaling to adapt static models.
- Dynamic Transfer: Combines residual and static convolutions to handle multiple domains.
- DRConv: Learns masks to apply region-specific filters efficiently.
Our method uses bitstream priors as conditions for dynamic adaptation, avoiding parameter search or learning.
3. Preliminaries
3.1. Hierarchical Quality Adjustment
Constant Rate Factor (CRF)
CRF ranges from 0 to 51 to balance compression efficiency and visual quality
Sequence-wise CRF (CRF_s)
By considering the sequence-wise CRF, the enhancement network can be tailored to handle videos of different compressison levels
Frame-wise CRF (CRF_i)
CRF value of each frame adjusted based on CRF_s so that lower CRF_i is assigned for I/P frames to maintain quality and higher CRF_i for B frames for compact representations

3.2. Redundancy Reduction
Partition Map
each frame are partitioned into blocks of varying sizes
=> We propose dynamically assigning filters based on the partition map that indicates region complexity
Motion Vector
motion vectors describe the relationship between current frame and its reference frames in a block-wise manner.
=> Motion vectors can effectively align reference frames with current frame although they are less precise than optical flow


img source : : https://deeprender.ai/blog/motion-compensation-and-prediction-h265
4. Codec-Aware Enhancement Framework
4.1. Overview
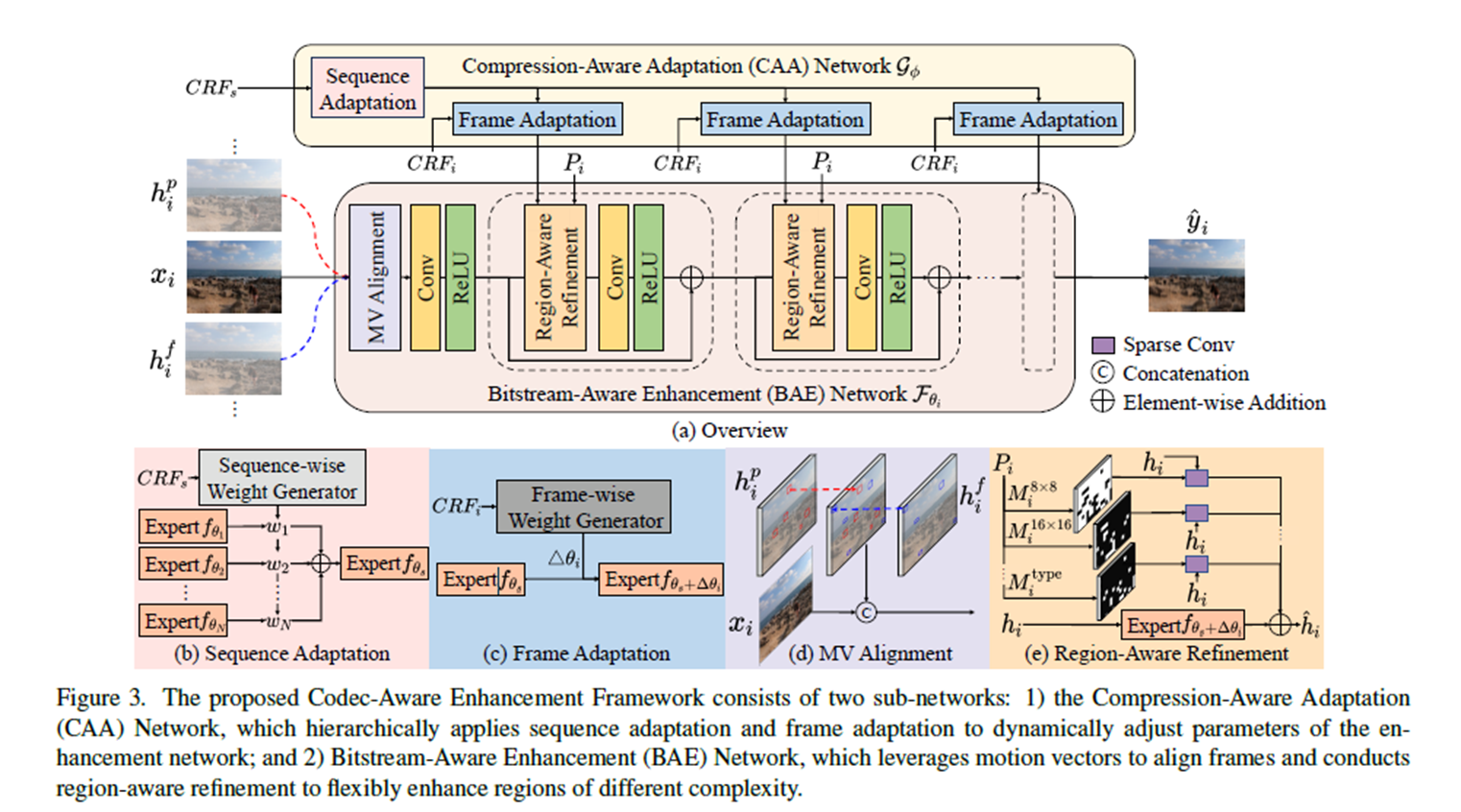
4.2. Compression-Aware Adaptation Network
CAA Networks G_ɸ utilizes CRF_s to estimate sequence-adaptive parameters and perform frame adaptation based on CRF_i

Sequence adaptation
we propose estimating sequence-adaptive parameters for the enhancement network



CRF_s is predicted only once and reused by subsequent frames
Frame adaptation
we propose to re-weight the sequence-based f_(θ_s) using frame-wise CRF_i
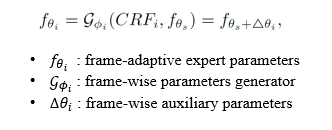

f_(θ_s) is used to construct the enhancement blocks, resulting in the frame-adaptive BAE network F _(θ_i)
4.3. Bitstream-Aware Enhancement Network
BAE Networks (F _(θ_i )) utilizes motion vectors to align reference frames

Motion Vector alignment
The warped reference feature are concatenated (channel dimension) with current frame along the channel dimension as input of the BAE network


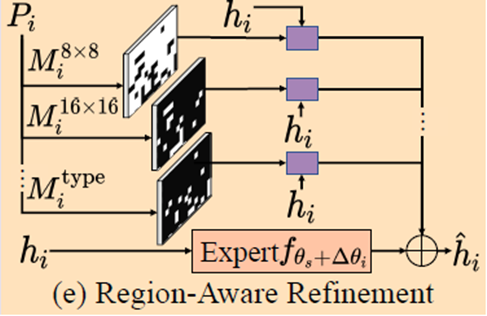
Region-aware alignment
We propose to dynamically assign different filters for regions based on the partition map.


4.4. Loss Function
We adopt Charbonnier penalty loss as the loss function and train the proposed codec-aware enhancement framework
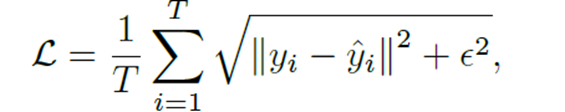
5. Experiments
5.1. Experimental Settings

5.2. Results
Evaluations are two-fold:
1)verifying the quality enhancement performance on seen, unseen, and highly compressed scenario.
2)evaluating the versatility to assist different downstream tasks on multiple compression settings
Quantitative results
Metrics : Param/M, FLOPs/G, Speed/ms, FPS, PSNR, SSIM

Qualitative results

5.2.2. Versatility Evaluation
Video Super-resolution
We adopt BasicVSR, IconVSR, and BasicVSR++ on the REDS4 dataset which are trained on ‘clean’ data without considering compression
Metrics : PSNR, SSIM
Result
inputs with Metabit fails to improve the performance of downstream VSR models.
our framework yields consistent improvement


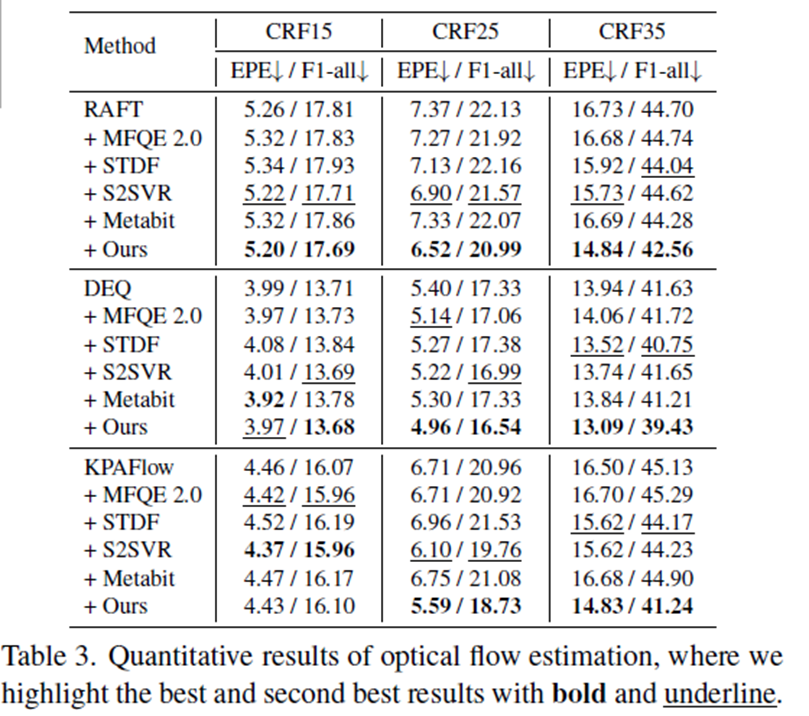
Optical Flow Estimation
We adopt RAFT, DEQ, KPAFlow and evaluate on the KITTI-2025 dataset
Metrics : EPE (end-point-error), F1-all loss
Results
reduces the EPE and F1-all loss across all baseline models

Video Object Segmentation
We adopt CTCN, DeAoT, QDMN and evaluate on DAVIS-17 val dataset
Metrics : Average, F score(boundary similarity), J (average IoU)
Results
the proposed method shows the best performance in improving accuracy across VOS models


Video Inpainting
We adopt E^2 FGVI on DAVIS-17 val dataset
Results
Pre-enhancing the compressed inputs with the proposed method notably refines the artifacts and distortions, yielding more visually pleasing results

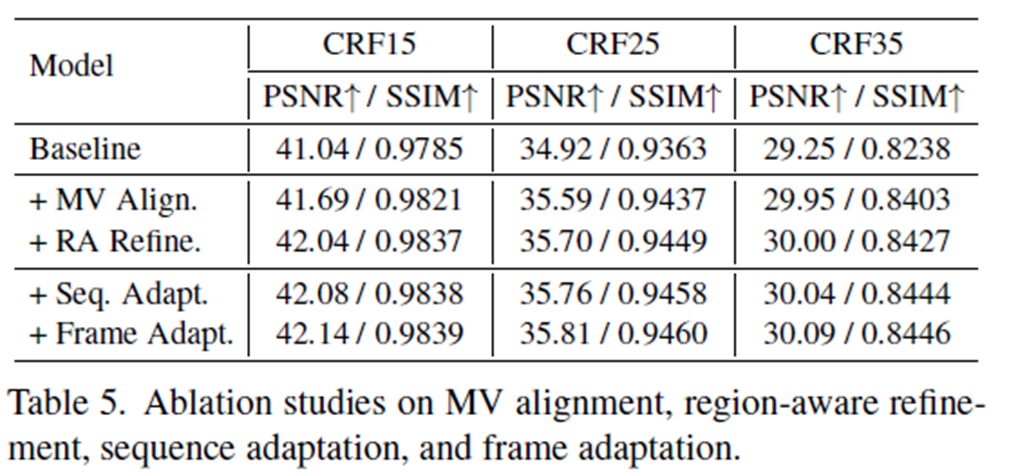
5.3. Ablation Studies
=> Each method is more effective than the baseline
6. conclusion
'Computer Science > AI' 카테고리의 다른 글
| 3DGS를 위한 COLMAP-GUI 사용법 (1) | 2025.05.09 |
|---|---|
| [3DGS] Compressed 3D Gaussian Splatting for Accelerated Novel View Synthesis (0) | 2025.05.01 |
| [3DGS] LightGaussian: Unbounded 3D Gaussian Compression with 15x Reduction and 200+ FPS (0) | 2025.04.21 |
| [3DGS] Text-to-3D using Gaussian Splatting / ver. Kor (0) | 2025.04.07 |
| [3DGS] Mip-Splatting: Alias-free 3D Gaussian Splatting / Ver.Kor (0) | 2025.03.31 |








